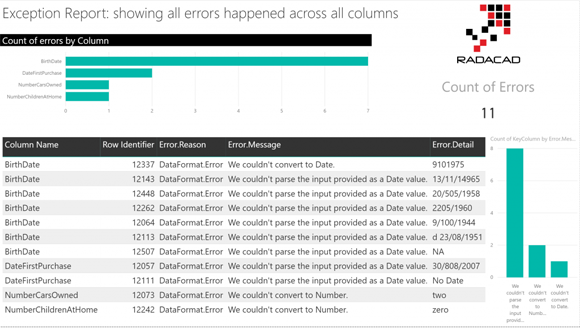
Отчеты об исключениях в Power Query и Power BI; Часть 2: Ловля ошибочных строк для всех столбцов в первой секции таблицы, глава 1
Ранее мы писали об использовании преобразований и функций Power Query для создания отчета об исключениях для Power BI. Тем не менее, метод, упомянутый там, производил только обработку исключений на основе одного столбца. В этой статье объясняется, как создавать отчеты об исключениях для всех столбцов во всей таблице. Необходимо пройти чуть больше шагов и обучения, чтобы реализовать весь процесс для всей таблицы.
Необходимое условие
Было бы полезно прочитать первую часть отчета об исключениях в этой статье здесь.
Вы можете скачать набор данных, использованный для этого примера, здесь.
Вступление
Метод сообщения об исключениях, который вы узнали в части 1, был сосредоточен на обработке ошибок для одного столбца. Этот метод работает лучше всего, если вы уже знаете, какой столбец вызывает ошибку. Однако во многих случаях вы не знаете, какой столбец вызвал (или вызовет) ошибку. Итак, эта статья нацелена на этот сценарий.
Важное примечание: обработка исключений - это процесс, который увеличивает время обновления. Определенно быстрее обрабатывать исключения для одного столбца, чем для всех столбцов во всей таблице. Настоятельно рекомендуем использовать метод, упомянутый в части 1, если вы уже знаете, какой столбец подвержен ошибкам в таблице.
Начнем с основ
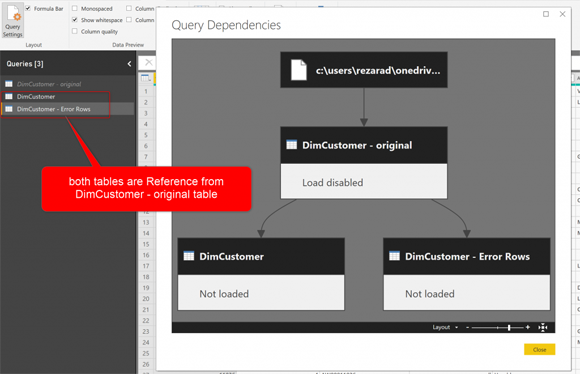
В первой части этой статьи упоминалось, что для правильной обработки ошибок вам нужно иметь три таблицы: первая таблица будет исходным источником, на вторую будет ссылаться исходная таблица, а ошибочные строки в ней будут удалены. И последняя таблица (которую мы называем таблицей ошибок) с сохраненными ошибочными строками. Теперь давайте начнем с этого плана.
Если вы не выполнили часть 1, вы можете начать с получения данных из файла, упомянутого выше, затем нажать кнопку Edit, чтобы перейти в Power Query Editor, а затем переименовать DimCustomer в DimCustomer – original. Отключите загрузку для этой таблицы, щелкнув правой кнопкой мыши и сняв флажок с Enable load.
DimCustomer - original - это таблица, полученная из источника данных и содержащая некоторые преобразования данных, которые могут вызвать ошибку. Эта таблица не загружается в Power BI (не включена проверка загрузки). Начните с создания двух ссылок из этой таблицы:
DimCustomer (таблица, которая будет использоваться в обычной отчетности в Power BI)
DimCustomer - Error rows (таблица, которая будет использоваться в качестве источника отчетов об исключениях).
Удалите строки с ошибками
Таблица DimCustomer - это таблица без ошибок, которую мы используем в обычных отчетах. Чтобы удалить строки ошибок, необходимо выбрать все столбцы в этой таблице (Ctrl + A), а затем выбрать Remove Rows -> Remove Errors.
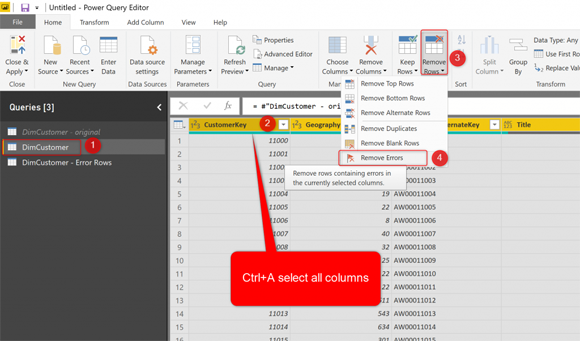
Это действие удалит ошибки. Тем не менее, есть проблема! Если вы посмотрите на код М, сгенерированный в строке формул, вы увидите, что код выглядит так:
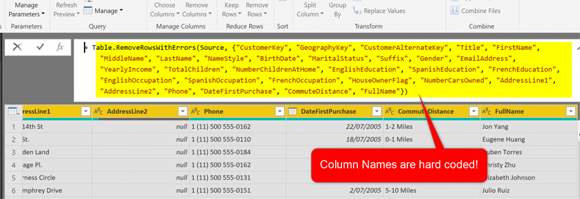
Это означает, что если позже в таблицу будет добавлен еще один столбец, содержащий ошибку, эта таблица больше не будет таблицей, очищенной от ошибок. Нам нужен лучший способ сделать это динамически. Нам нужно получить список столбцов из таблицы и использовать его в качестве источника для функции RemoveRowsWithErrors.
Table.ColumnNames: список всех имен столбцов в таблице
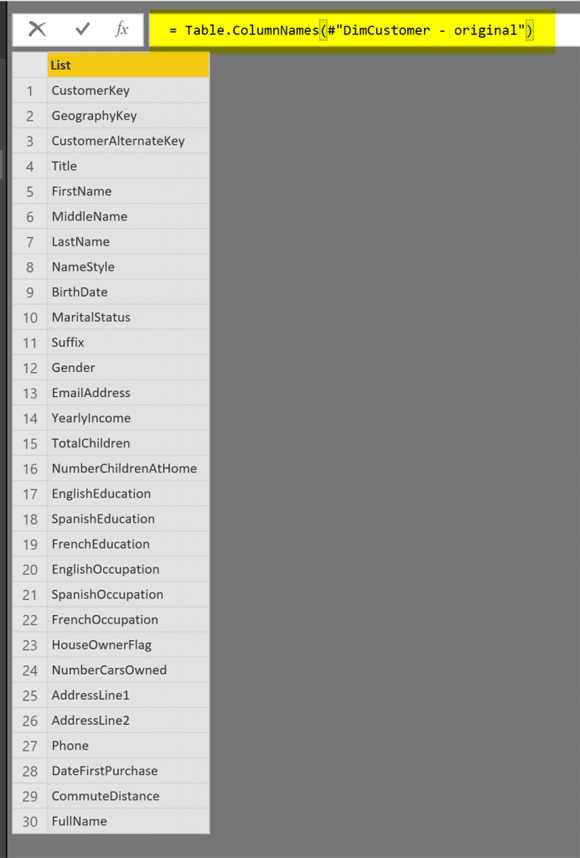
Table.ColumnNames - это функция, которая получает имя таблицы в качестве источника и выдаст вам список имен столбцов в качестве выходных данных. Table.ColumnNames - это функция, которую можно использовать так:
<list output> = Table.ColumnNames(<table name>)
Пример вывода этой функции (запускается в пустом скрипте Power Query для вышеупомянутой таблицы):
= Table.ColumnNames(#"DimCustomer - original")
Удалите строки с ошибками с помощью списка динамических столбцов
Теперь все, что нам нужно сделать, это использовать выходные данные Table.ColumnNames в качестве входных данных функции Table.RemoveRowsWithErrors. Выделена та часть кода, которая должна быть заменена на Table.ColumnNames;

А вот новый код:
= Table.RemoveRowsWithErrors (Source, Table.ColumnNames (Source))
Как вы заметили, имя таблицы - «Source», поскольку оно происходит от предыдущего шага, называемого «Source».
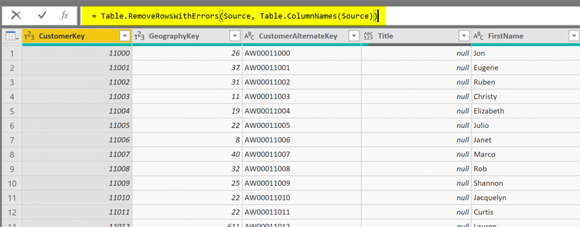
Прекрасная работа! Теперь эта таблица (DimCustomer) является таблицей без каких-либо ошибок. Даже если количество столбцов в исходной таблице изменится, оно все равно будет действительной таблицей. Давайте посмотрим, что мы можем сделать с другой таблицей.
Храните строки с ошибками
Для таблицы DimCustomer - Error Rows у нас снова тот же сценарий. Используйте Keep rows with errors. Он будет жестко кодировать имена столбцов, и вам нужно будет заменить его на вывод Table.ColumnNames, как показано ниже:
= Table.SelectRowsWithErrors(Source, Table.ColumnNames(Source))
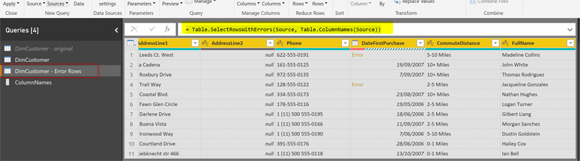
Теперь в этой таблице есть все строки ошибок, которые могли возникнуть в любом из столбцов. Наш следующий шаг - искать в каждом ряду столбец, который вызвал ошибку. Потому что не все столбцы вызвали ошибку в каждой строке. Чтобы найти его и затем указать на него, нам нужен идентификатор строки. Способ различить этот ряд покажем позже. Нам нужен ключевой столбец для таблицы.
Unpivot: столбцы как строки
Теперь нам нужно иметь столбцы в структуре, как показано ниже:
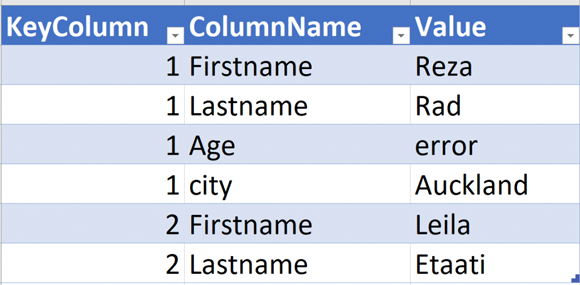
Вместо столбцов у нас будут строки, а затем мы можем фильтровать только те, в которых их значение является ошибкой. Одно из лучших преобразований для этой работы – Unpivot. Тем не менее, отключение может закончиться так:
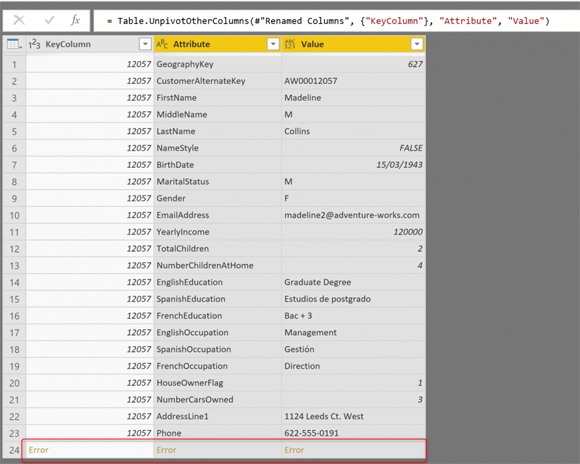
Что случилось? У нас есть 11 строк в таблице ошибок и 30 столбцов в каждой строке (минус ключевой столбец - 29). Это означает, что эта новая таблица должна иметь 11 * 29 строк, что составляет 319 строк. Но, как видите, в таблице 24 строки. Процесс остановился при попадании первой ошибки.
Unpivot не защищен от ошибок, и если у вас есть ошибки в вашем наборе данных, вы должны сначала очистить их перед использованием этой функции. Поэтому мы должны найти другой способ, который дает нам тот же результат. Нам нужно получить список значений в каждой строке в виде таблицы, а затем развернуть его. Начнем с получения списка значений в каждой строке.
Если вы выполнили действие Unpivot, упомянутое на этом шаге, удалите его. Это объяснение было просто для того, чтобы показать вам, почему мы не можем его использовать и должны использовать метод, который немного отличается и включает больше шагов.
Индикатор текущей строки: _
Если вы никогда не использовали символ «_», это один из лучших моментов, чтобы узнать об этом. Символ подчеркивания (_) при использовании сам по себе (не как часть текста) означает текущую строку! Если вы используете его в списке, который имеет только одно значение в строке, он возвращает это значение. Если вы используете его в таблице, он возвращает текущую строку в этой таблице, и каждая строка в таблице является записью.
Чтобы увидеть это и понять лучше, давайте добавим пользовательский столбец, а затем в качестве выражения просто напишем один символ: _
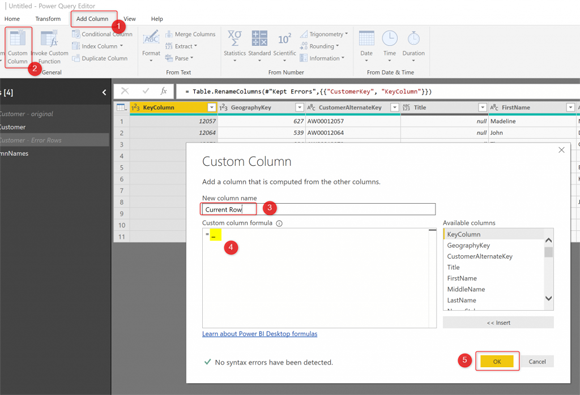
Ваша таблица будет выглядеть следующим образом: в конце таблицы добавляется новый столбец с одной записью в каждой строке. Эта запись включает в себя все значения этой строки.
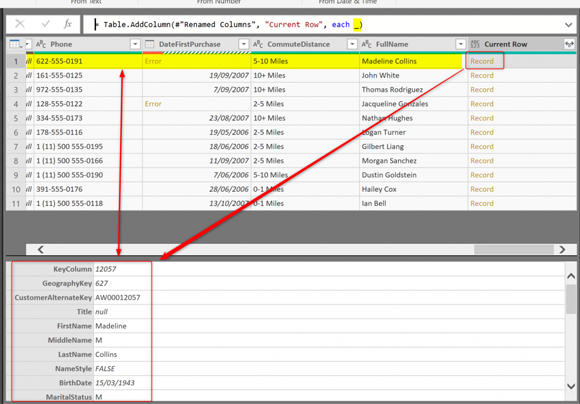
У нас есть метод для извлечения содержимого строки как одного объекта, и все это с помощью волшебного индикатора текущей строки: _.
Теперь наш следующий шаг - развернуть его, но не используя обычное раскрытие, потому что если вы развернете запись в таблице, столбцы этой записи будут добавлены в таблицу, что означает, что мы вернемся в то же место, где были раньше.
Если вы преобразуете запись в таблицу, у вас будет два столбца в качестве выходных данных; имена столбцов в записи и значения столбцов. И тогда это будет структура, которая может быть расширена без возврата всех столбцов на место. Итак, давайте преобразуем это значение в таблицу.
Преобразование текущей записи в таблицу: Record.ToTable
Добавьте еще один пользовательский столбец и на этот раз напишите приведенное ниже выражение, чтобы преобразовать эту запись в таблицу:
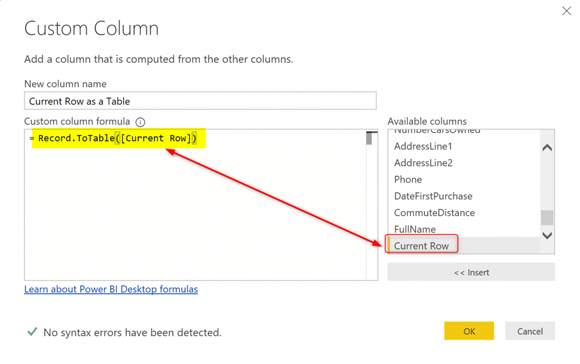
Выражение будет выглядеть следующим образом:
Record.ToTable ([Current Row])
Теперь таблица будет иметь столбец в конце, с таблицей в каждой строке, и эта таблица является содержимым текущей строки (но в формате таблицы);
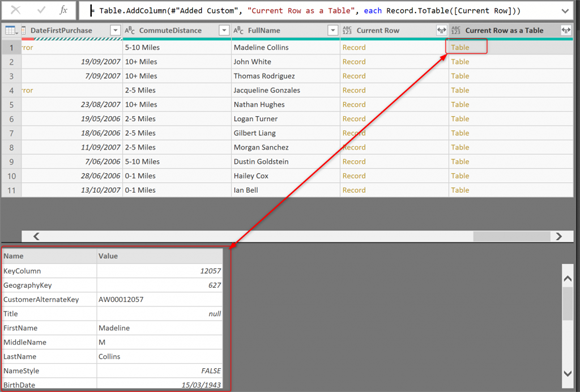
Мы могли бы сделать и этот шаг, и шаг перед использованием одного действия с Record.ToTable (_). Однако мы разделили его на два этапа, чтобы прояснить концепцию _.
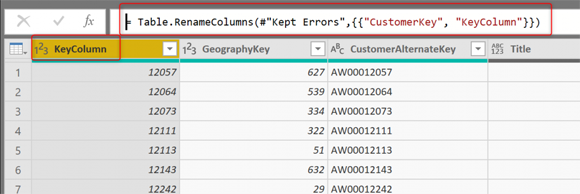
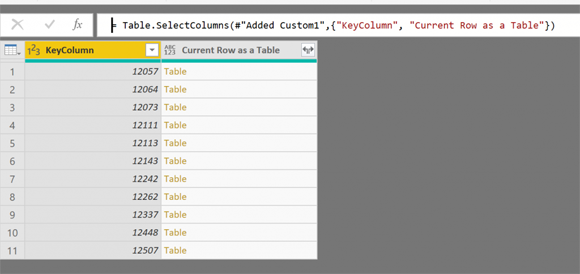
Имея вложенную таблицу, мы можем удалить все остальные столбцы и сохранить только KeyColumn и столбец, содержащий таблицы;
Расширение
Наш следующий шаг - расширить базовую таблицу;
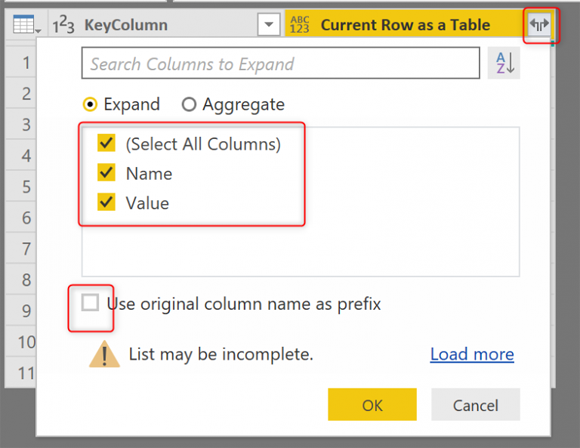
Базовая таблица имеет только Name (имена столбцов) и Value (значения ячеек), и вот расширенный вывод:
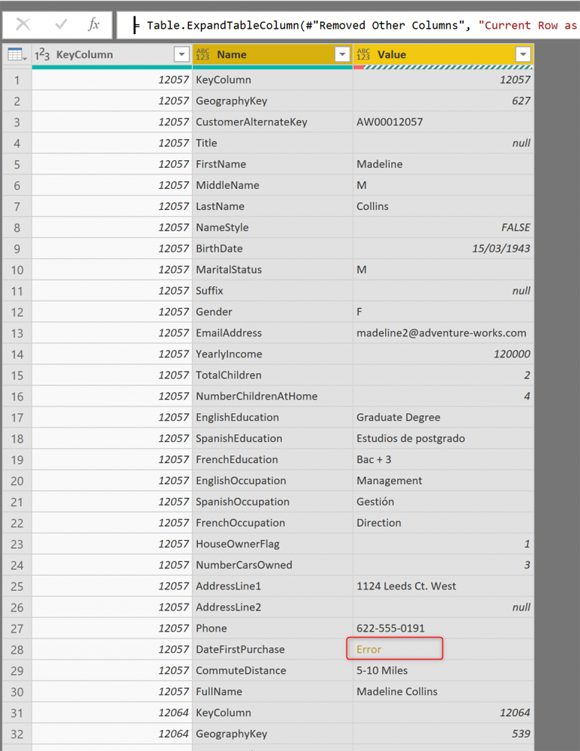
Первый столбец в этой таблице - это KeyColumn для каждой строки. Теперь для каждой строки в предыдущей структуре таблицы у нас есть несколько строк в этой новой структуре, по одной строке на столбец, в каждой строке, в дополнение к KeyColumn, вы можете видеть имя столбца (Name и строку значение в этой ячейке (Value. И вы можете видеть, что это значение строки иногда имеет ошибку.
Следующие шаги
Шаги все еще продолжаются с некоторыми другими преобразованиями. Однако, поскольку это сделало бы эту статью длинным постом, мы расскажем об этом в следующем посте. Оставайтесь с нами для раздела 2 этой статьи, которая будет частью 3 отчета об исключениях в Power BI. В конце процесса у нас будет такой отчет: