Знакомство с кластерами больших данных Microsoft SQL Server 2019
Недавно на конференции Microsoft Ignite было объявлено, что SQL Server 2019 теперь находится в предварительном просмотре и что SQL Server 2019 будет включать Apache Spark и распределенную файловую систему Hadoop (HDFS) для масштабируемого вычисления и хранения. Эта новая архитектура, которая объединяет механизм базы данных SQL Server, Spark и HDFS в единую платформу данных, называется кластером больших данных - «big data cluster».
В течение 25 лет Microsoft SQL Server приводил в действие организации, основанные на данных. По мере роста разнообразия типов данных и объема этих данных число типов баз данных резко возросло. На протяжении многих лет SQL Server не отставал, добавляя поддержку данных XML, JSON, in-memory и graph в базе данных. Он стал гибким механизмом базы данных, на который предприятия могут рассчитывать для получения ведущих в отрасли производительности, высокую доступности и безопасности. Тем не менее, один экземпляр SQL Server никогда не был спроектирован или создан как механизм базы данных для аналитики в масштабе петабайтов или экзабайтов. Он также не был предназначен для масштабирования вычислений для обработки данных или машинного обучения, а также для хранения и анализа данных в неструктурированных форматах, таких как медиафайлы.
Предварительный просмотр SQL Server 2019 расширяет свою унифицированную платформу данных для охвата больших и неструктурированных данных путем развертывания нескольких экземпляров SQL Server вместе с Spark и HDFS в качестве кластера больших данных.
Когда Microsoft добавила поддержку Linux в SQL Server 2017, она открыла возможность глубокой интеграции SQL Server с Spark, HDFS и другими крупными компонентами данных, которые в основном базируются на Linux. Кластеры больших данных SQL Server 2019 переходят на следующую ступень, полностью охватывая современную архитектуру развертывания приложений - даже с точки зрения состояния, таких как база данных, - как контейнеры на Kubernetes. Развертывание больших кластеров данных SQL Server 2019 на Kubernetes обеспечивает предсказуемое, быстрое и эластично масштабируемое развертывание независимо от того, где оно развертывается. Кластеры больших данных могут быть развернуты в любом облаке, где есть управляемая служба Kubernetes, такая как Azure Kubernetes Service (AKS) или в локальных кластерах Kubernetes, таких как AKS на стек Azure. Встроенные службы управления в большом кластере данных обеспечивают анализ журналов, мониторинг, резервное копирование и высокую доступность через портал администратора, обеспечивая постоянный опыт управления везде, где развертывается большой кластер данных.
Механизм реляционной базы данных SQL Server 2019 в кластере больших данных использует эластично масштабируемый уровень хранения, который объединяет SQL Server и HDFS для масштабирования до петабайт хранения данных. Механизм Spark, который теперь является частью SQL Server, позволяет инженерам и ученым по данным использовать возможности библиотек для подготовки данных с открытым исходным кодом и библиотек запросов для обработки и анализа данных большого объема в масштабируемом распределенном внутрипамятном уровне вычисления.
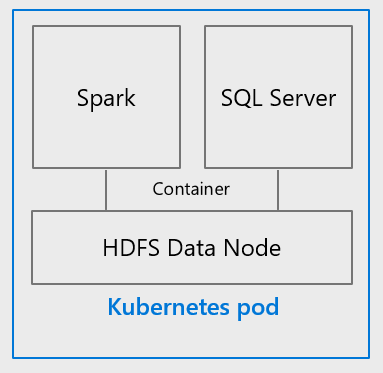
Рисунок 1: SQL Server и Spark развернуты вместе с HDFS, создавая общее озеро данных
Интеграция данных посредством виртуализации данных
Хотя извлечение, преобразование, загрузка (ETL) имеет свои варианты использования, альтернативой ETL является виртуализация данных, которая объединяет данные из разных источников, местоположений и форматов без репликации или перемещения данных для создания единого «виртуального» уровня данных , Виртуализация данных позволяет унифицировать службы данных для поддержки нескольких приложений и пользователей. Уровень виртуальных данных, иногда называемый центром данных, позволяет пользователям запрашивать данные из многих источников через единый унифицированный интерфейс. Доступ к чувствительным наборам данных можно контролировать из одного места. Задержки, присущие ETL, не должны применяться; данные всегда могут быть актуальными. Затраты на хранение и сложность управления данными сведены к минимуму.
Кластеры больших данных SQL Server 2019 с улучшениями в PolyBase действуют как центр данных для интеграции структурированных и неструктурированных данных со всей совокупности данных - SQL Server, Azure SQL Database, Azure SQL Data Warehouse, Azure Cosmos DB, MySQL, PostgreSQL, MongoDB, Oracle, Teradata, HDFS и т. Д. - используя привычные рамки программирования и инструменты анализа данных.
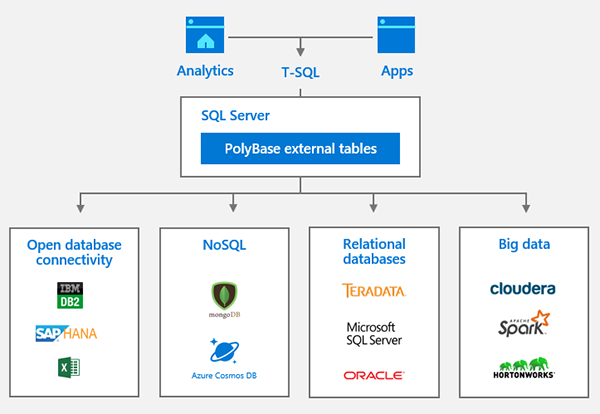
Рисунок 2: Источники данных, которые могут быть интегрированы с помощью PolyBase в SQL Server 2019
В кластерах больших данных SQL Server 2019 механизм SQL Server получил возможность считывать файлы HDFS, такие как CSV и паркетные файлы, с помощью экземпляров SQL Server, размещенных на каждом узле данных HDFS, для фильтрации и агрегирования данных локально и параллельно через все узлы данных HDFS.
Производительность запросов PolyBase в кластерах больших данных SQL Server 2019 может быть дополнительно повышена путем распределения агрегации перекрестных разделов и перетасовки отфильтрованных результатов запроса для «вычисления пулов», состоящих из нескольких экземпляров SQL Server, которые работают вместе.
Когда вы объединяете расширенные соединители PolyBase с пулами данных кластеров больших данных SQL Server 2019, данные из внешних источников данных можно разделить и кэшировать по всем экземплярам SQL Server в пуле данных, создав «масштабируемую витрину данных». В этом пуле данных может быть более одного масштабируемой витрины данных, а в витрине данных можно комбинировать данные из нескольких внешних источников данных и таблиц, что упрощает интеграцию и кэширование комбинированных наборов данных из нескольких внешних источников.
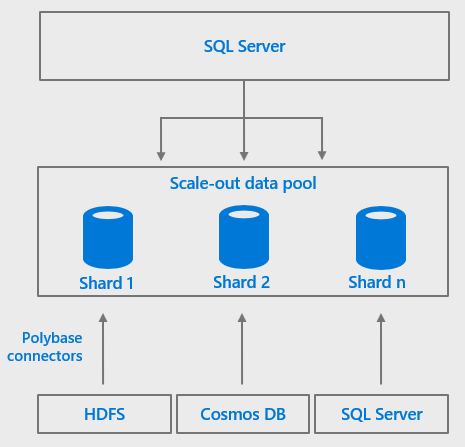
Рисунок 3: Использование масштабируемого пула данных для кэширования данных из внешних источников данных для повышения производительности
Полная платформа ИИ, построенная на совместном озере данных с SQL Server, Spark и HDFS
Кластеры больших данных SQL Server 2019 упрощают объединение больших наборов данных к размерным данным, обычно хранящимся в реляционной базе данных предприятия, что облегчает людям и приложениям, использующим SQL Server, запрос больших данных. Значимость больших данных значительно возрастает, когда они находятся не только в руках ученых по данным и инженеров по большим данным, но также включены в отчеты, информационные панели и приложения. В то же время ученые по данным могут продолжать использовать большие инфраструктурные инструменты данных, а также использовать простой доступ в режиме реального времени к высокоценным данным в SQL Server, потому что все это часть единой интегрированной системы.
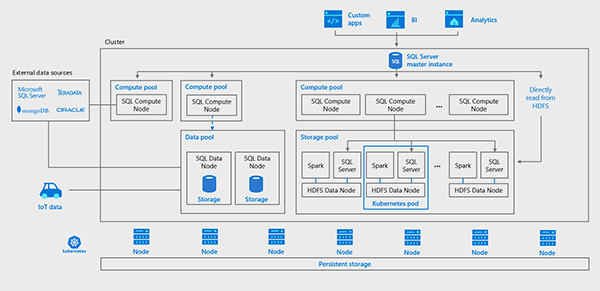
Рисунок 4: Масштабируемая архитектура вычислений и хранения в кластере большмх данных SQL Server 2019
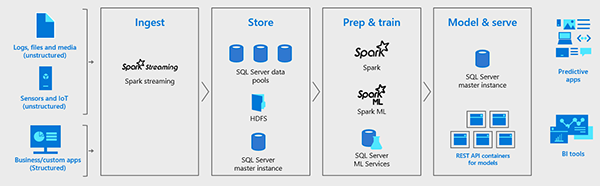
Кластеры больших данных SQL Server 2019 обеспечивают полноту AI-платформы. Данные могут легко проглатываться через Spark Streaming или традиционные вставки SQL и сохраняться в HDFS, реляционных таблицах, графиках или JSON / XML. Данные могут быть подготовлены с использованием либо Spark-заданий, либо запросов Transact-SQL (T-SQL), и загружаться в учебные процедуры модели машинного обучения в любом экземпляре Spark или SQL Server с использованием различных языков программирования, включая Java, Python, R, и Scala. Полученные модели затем могут быть введены в действие в операциях пакетного подсчета в Spark, в хранимых процедурах T-SQL для подсчета в реальном времени или инкапсулированы в контейнеры REST API, размещенные в кластере больших данных.
Кластеры больших данных SQL Server предоставляют все инструменты и системы для сбора, хранения и подготовки данных для анализа, а также для обучения моделей машинного обучения, хранения моделей и их практической реализации.
Данные можно использовать с помощью Spark Streaming, вставляя данные непосредственно в HDFS через API HDFS или вставляя данные в SQL Server с помощью стандартных запросов на вставку T-SQL. Данные могут храниться в файлах в HDFS или разбиваться на разделы и храниться в пулах данных или сохраняться в главном экземпляре SQL Server в таблицах, графиках или JSON / XML. И T-SQL, и Spark можно использовать для подготовки данных путем запуска пакетных заданий для преобразования данных, их агрегации или выполнения других задач обработки данных.
Ученые по данным могут выбрать, использовать либо службы машинного обучения SQL Server в главном экземпляре для запуска сценариев обучения R, Python или Java, либо использовать Spark. В любом случае для обучения моделей можно использовать полную библиотеку библиотек обучения машин с открытым исходным кодом, таких как TensorFlow или Caffe.
Наконец, как только модели будут обучены, они могут быть задействованы в главном экземпляре SQL Server с использованием собственного скоринга в реальном времени с помощью функции PREDICT в хранимой процедуре в главном экземпляре SQL Server; или вы можете использовать пакетный подсчет по данным в HDFS с помощью Spark. В качестве альтернативы, используя инструменты, поставляемые с кластером больших данных, инженеры по данным могут легко обернуть модель в REST API и предоставить модель API + в качестве контейнера на большом кластере данных в качестве скорингового микросервиса для легкой интеграции в любое приложение.
Важно отметить, что весь этот конвейер происходит в контексте кластера больших данных SQL Server. Данные никогда не покидают границы безопасности и соответствия требованиям для перехода на внешний сервер машинного обучения или компьютера ученого по данным. Для обработки данных доступна полная мощность аппаратного обеспечения, лежащего в основе кластера больших данных, и вычислительные ресурсы могут быть эластично масштабированы вверх и вниз по мере необходимости.
Azure Data Studio - инструмент для управления и анализа данных с открытым исходным кодом, предназначенный для администраторов баз данных, ученых и инженеров по данным. Новые расширения для Azure Data Studio интегрируют пользовательский интерфейс для работы с реляционными данными в SQL Server с большими данными. Новый браузер HDFS позволяет аналитикам, ученым и инженерам по данным легко просматривать файлы и каталоги HDFS в кластере больших данных, загружать или выгружать файлы, открывать их и удалять, если необходимо. Новые встроенные блокноты в Azure Data Studio построены на Jupyter, позволяя ученым и инженерам данных писать код Python, R или Scala с подсветкой Intellisense и синтаксисом перед отправкой кода в виде заданий Spark и просмотра результатов inline. Блокноты обеспечивают совместную работу между членами команды проекта анализа данных. Наконец, мастер внешних таблиц упрощает процесс создания внешних источников данных и таблиц, включая сопоставления столбцов.
Заключение
Кластеры больших данных SQL Server 2019 - это непревзойденный новый способ использования SQL Server для создания высокоценных реляционных данных и объемных больших данных на единой масштабируемой платформе данных. Предприятия могут использовать возможности PolyBase для виртуализации своих хранилищ данных, создания озер данных и создания масштабируемых витрин данных в единой безопасной среде без необходимости внедрения медленных дорогостоящих ETL-конвейеров. Это делает приложения и анализ данных лучше реагирующими и более продуктивными. Большие кластеры данных SQL Server 2019 предоставляют полную платформу AI для доставки интеллектуальных приложений, которые помогают сделать любую организацию более успешной.