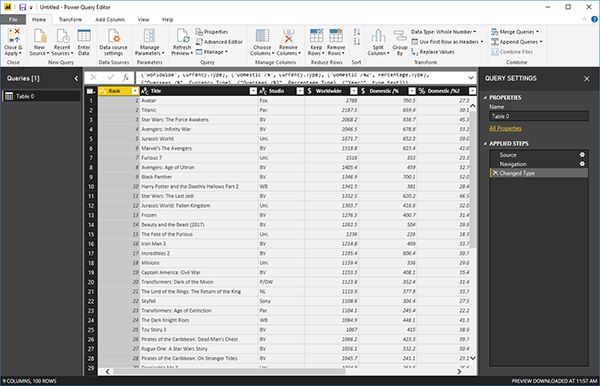
Запрос больших данных, хранящихся в файлах csv или parquet, из любой хранимой процедуры
Каждый облачный провайдер в настоящее время имеет бессерверный интерактивный запрос, который использует стандартный SQL для анализа данных.
Что касается крупнейших поставщиков облачных вычислений, у нас есть аналитика Azure Data Lake, Google BigQuery и Amazon Athena. У нас есть некоторый опыт работы с сервисом Athena, и мы должны сказать, что это потрясающе.
Сегодня мы покажем вам, как вы можете использовать Management Studio или любую хранимую процедуру для запроса данных, хранящихся в файле csv, находящемся в хранилище S3. В качестве примера мы используем формат CSV-файлов, столбчатый PARQUET дает гораздо лучшую производительность.
Мы собираемся:
- Поместить простой CSV-файл в хранилище S3.
- Создать внешнюю таблицу в сервисе Athena по веществу файла данных
- Создать связанный сервер с Athena внутри SQL Server
- Использовать OPENQUERY для запроса данных.
Служба Athena построена на вершине Presto, распределенного механизма SQL, а также использует Apache Hive для создания, изменения и удаления таблиц. Вы можете запускать инструкции ANSI SQL в редакторе запросов Athena, запуская его из пользовательского интерфейса веб-служб AWS. Вы можете использовать сложные объединения, функции окна и многие другие замечательные возможности языка SQL. Использование Athena устраняет необходимость в ETL, поскольку он проектирует вашу схему в файлах данных во время запроса.
Давайте создадим базу данных в редакторе запросов Athena.

В качестве следующего шага я поставлю этот файл csv на S3. Кстати, Athena поддерживает форматы JSON, tsv, csv, PARQUET и AVRO.
Загрузите следующий файл в корзину S3 (не помещайте заголовок столбцов в файл):
Вернитесь в Athena для создания внешней таблицы через папку S3. После этого вы можете добавить больше файлов в одну папку, и ваши запросы будут возвращать новые данные.
Теперь я могу запросить данные:
В качестве следующего шага мы создадимм связанный сервер из нашего экземпляра SQL Server, потому что мы хотели бы разгрузить большой запрос данных в Athena. Конечно, мы используем в этом примере крошечный файл данных, но в реальной жизни мы иногда запрашиваем 300 ГБ файлов данных в одном запросе, и это занимает несколько секунд.
У Athena есть драйвер ODBC, мы установим его на машине SQL Server (экземпляр AWS EC2 для этого примера).
Вот ссылка на установку: https://s3.amazonaws.com/athena-downloads/drivers/ODBC/Windows/Simba+Athena+1.0+64-bit.msi
Настройка соединения ODBC. Важно, выберите опцию Authentication Option и заполните AccessKey и SecretKey, у которых есть разрешения на доступ к хранилищу S3. Выходное местоположение S3 ниже будет содержать файлы csv с результатами ваших запросов. Не забудьте периодически очищать выходные файлы.
Осталось настроить Linked Server внутри Management Studio с помощью поставщика OLEDB для ODBC.
EXEC master.dbo.sp_addlinkedserver @server = N'DWH_ATHENA', @srvproduct=N'', @provider=N'MSDASQL', @datasrc=N'DWH_ATHENA'
GO
EXEC master.dbo.sp_addlinkedsrvlogin@rmtsrvname=N'DWH_ATHENA',@useself=N'False',@locallogin=NULL,@rmtuser=N'*******',@rmtpassword='*********'
GO
Замените @rmtuser и @rmtpassword ключом доступа AWS и секретным ключом, и теперь мы можем запросить файлы данных из любого скрипта или хранимой процедуры.
Есть одна важная вещь, которую вам нужно знать. . Регулярные адресаты ODBC SQL Server запрашивают режим отправления «select *» на связанный сервер и выполняют фильтрацию внутри SQL Server. Это очень плохо для нас, поскольку мы хотели разгрузить всю работу Athena, и мы не хотим получать все данные. Способ преодоления этого - использование OPENQUERY.
Вот пример запроса, который использует связанный сервер. Удаленный запрос опустил всю фильтрацию и получил ВСЕ столбцы из удаленной таблицы, и фильтр применяется позже, на этапе «Filter».
Результат:
Разве не удивительно, что можно хранить данные строк в файлах и запрашивать их с минимальными усилиями со стороны SQL Server?