Высокая доступность MySQL на GitHub
GitHub использует MySQL в качестве основного хранилища данных для всех объектов, отличных от git, и его доступность имеет решающее значение для работы GitHub. Сам сайт, API-интерфейс GitHub, аутентификация и многое другое, - все требуют доступа к базе данных. Мы запускаем несколько кластеров MySQL, обслуживающих наши различные сервисы и задачи. В наших кластерах используется классическая настройка “мастер-реплики”, где один узел в кластере (мастер) способен принимать записи. Остальные узлы кластера (реплики) асинхронно воспроизводят изменения от мастера и обслуживают наш трафик чтения.
Наличие главных узлов особенно важно. Без мастера кластер не может принимать записи: любые записи, которые необходимо сохранить, не могут быть сохранены. Любые входящие изменения, такие как коммиты, проблемы, создание пользователей, обзоры, новые репозитории и другие, потерпят неудачу.
Для поддержки записей нам явно необходим доступный узел записи, мастер кластера. Но не менее важно то, что мы должны иметь возможность идентифицировать или обнаружить этот узел.
В случае сбоя, скажем, сценарий сбоя главного окна, мы должны обеспечить существование нового мастера, а также иметь возможность быстро афишировать его подлинность. Время, необходимое для обнаружения сбоя, запуска отказоустойчивости и объявления подлинности нового мастера, и составляет общее время отключения.
Этот пост иллюстрирует решение GitHub по обеспечению высокой доступности и основных сервисов MySQL, которое позволяет нам надежно выполнять работу с несколькими вычислительными центрами, быть терпимым к изоляции центра обработки данных и достигать коротких периодов отключения при сбое.
Цели высокой доступности
Решение, описанное в этом сообщении, повторяет и улучшает предыдущие решения высокой доступности (HA), реализованные в GitHub. По мере нашего масштабирования, наша стратегия HA MySQL должна адаптироваться к изменениям. Мы хотим иметь аналогичные стратегии HA для нашего MySQL и других сервисов в GitHub.
При рассмотрении высокой доступности и обнаружения услуг некоторые вопросы могут привести вас к соответствующему решению. Неполный список вопросов может включать:
- Сколько времени простоя вы можете допустить?
- Насколько надежно обнаружение сбоев? Можете ли вы допустить ложные срабатывания (преждевременные отказы)?
- Насколько надежным является переход на другой ресурс? Где это может произойти?
- Насколько хорошо работает решение в межсетевом центре? В сетях с низкой и высокой задержкой?
- Будет ли решение допускать полный отказ центра обработки данных (DC) или изоляцию сети?
- Какой механизм, если таковой имеется, предотвращает или смягчает сценарии split-brain (когда два сервера, утверждающие, что они являются хозяином данного кластера, независимо друг от друга и неосознанно друг к другу, принимают записи)?
- Можете ли вы позволить себе потерю данных? До какой степени?
Чтобы проиллюстрировать некоторое из вышесказанного, давайте сначала рассмотрим нашу предыдущую итерацию HA и почему мы ее изменили.
Отказ от открытия на основе VIP и DNS
В нашей предыдущей итерации мы использовали:
- оркестратор для обнаружения и восстановления после отказа,
- VIP и DNS для открытия мастера.
На этой итерации клиенты обнаружили узел записи с использованием имени, например. mysql-writer-1.github.net. Имя разрешено для виртуального IP-адреса (VIP), который будет приобретать главный хост.
Таким образом, обычно клиенты просто разрешали бы имя, подключались к разрешенному IP-адресу и находили мастер-прослушивание с другой стороны.
Рассмотрим эту топологию репликации, охватывающую три разных центра обработки данных:
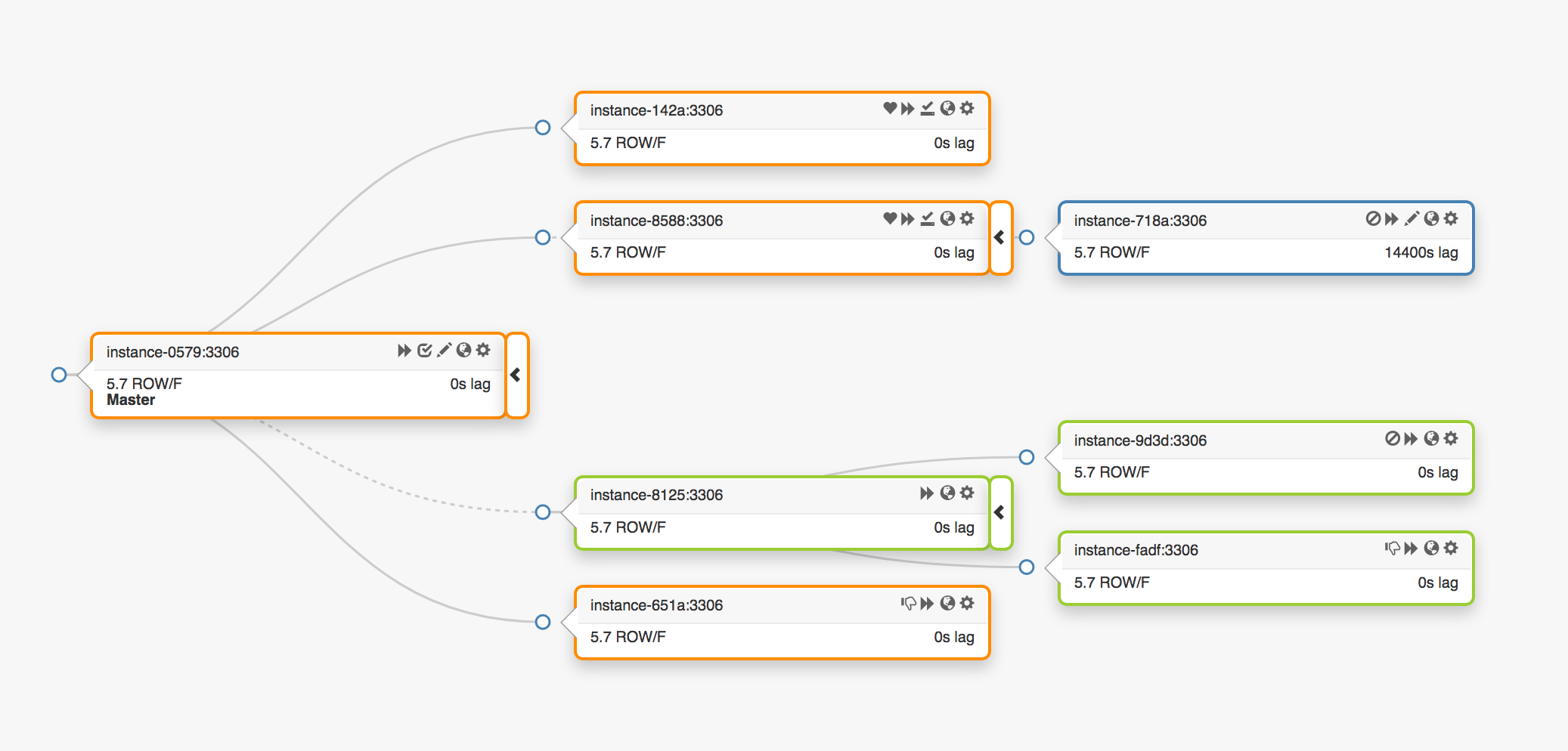
В случае сбоя мастера новый сервер, один из реплик, должен быть преобразован на своем месте.
оркестратор будет обнаруживать сбой, преобразовывать нового мастера, а затем действовать, чтобы переназначить имя/VIP. Клиенты фактически не знают личность мастера: все, что у них есть, это имя, и это имя теперь должно быть разрешено для нового мастера. Однако учтите:
VIPы являются кооперативными: они утверждаются и принадлежат самим серверам баз данных. Чтобы получить или освободить VIP, сервер должен отправить запрос ARP. Сервер, владеющий VIP, должен сначала освободить его до того, как его получил новый преобразованный мастер. Это несет некоторые нежелательные эффекты:
- Последовательная операция перехода на другой ресурс сначала свяжется с вышедшим из строя мастером и попросит, чтобы он освободил VIP, а затем свяжется с недавно преобразованным мастером и попросите его присвоить VIP. Что делать, если старый мастер не может быть достигнут или отказывается отпустить VIP? Учитывая, что на этом сервере есть сценарий сбоев, не исключено, что он не сможет ответить своевременно или вообще не отреагирует.
- У нас может получиться split-brain: два мастера утверждают, что имеют один и тот же VIP. Различные клиенты могут подключаться к любому из этих серверов, в зависимости от кратчайшего сетевого пути.
- Источник истины здесь зависит от сотрудничества двух независимых серверов, и эта настройка ненадежна.
- Даже если старый мастер взаимодействует, рабочий процесс тратит драгоценное время: при переходе к новому мастеру возникает ожидание, когда мы свяжемся с старым мастером.
- И даже по мере того, как изменяется VIP, существующие клиентские соединения не гарантируют отключение от старого сервера, и мы все еще можем столкнуться со split-brain.
В некоторых частях нашей настройки VIPы связаны физическим расположением. Они принадлежат коммутатору или маршрутизатору. Таким образом, мы можем переназначить VIPов на совместно расположенных серверах. В частности, в некоторых случаях мы не можем назначить VIP для сервера, продвигаемого в другом центре обработки данных, и должны внести изменение DNS.
- Изменения DNS занимают больше времени для распространения. Клиенты кэшируют DNS-имена для предварительно настроенного времени. Переключение на перекрестный DC означает увеличение времени простоя: потребуется больше времени, чтобы все клиенты знали о подлинности нового мастера.
Только этих ограничений было достаточно, чтобы подтолкнуть нас к поиску нового решения, но для еще большего рассмотрения были следующие:
- Мастера сами вводили себе пульсацию с помощью службы pt-heartbeat с целью измерения задержки и регулирования нагрузки. Служба должна была начаться с нового преобразованного мастера. Если возможно, служба должна быть отключена на старом мастере.
- Аналогичным образом, введение Pseudo-GTID управлялось мастерами самостоятельно. Нужно было бы начать это на новом мастере и остановить на старом.
- Новый мастер был установлен как записываемый. Старый мастер должен был быть установлен как read_only, если это возможно.
Эти дополнительные шаги были фактором, способствующим суммарному времени отключения, и ввели свои собственные сбои и трения.
Решение сработало, и у GitHub были успешные отказы MySQL, которые шли хорошо под радаром, но мы хотели, чтобы наша HA улучшила следующее:
- Была бы независима по отношению к центру обработки данных
- Была бы терпимой к сбою ЦОД.
- Удаляла бы ненадежные совместные рабочие процессы.
- Сокращала бы общее время простоя.
- В максимально возможной степени имела бы отказоустойчивые системы без потерь.
Решение HA GitHub: orchestrator, Consul, GLB
Наша новая стратегия, наряду с улучшением обеспечения, решает или смягчает многие из вышеперечисленных проблем. В сегодняшней установке HA мы имеем:
- orchestrator для запуска обнаружения и восстановления после сбоев. Мы используем настройку orchestrator/raft поперечного DC, как показано ниже.
- Hashicorp’s Consul для обнаружения службы.
- GLB / HAProxy в качестве прокси-уровня между клиентами и узлами-носителями.
- anycast для сетевой маршрутизации.
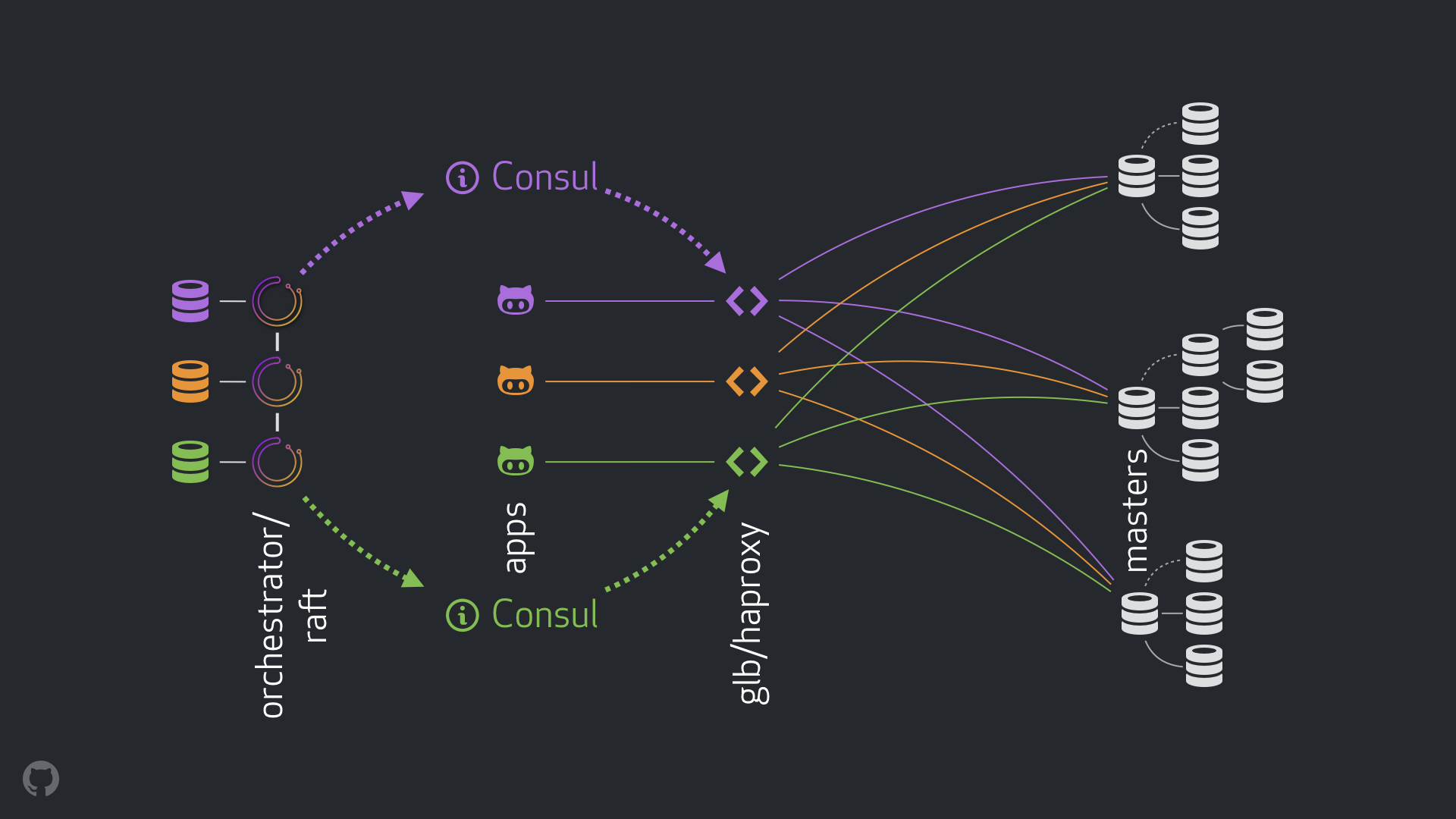
Новая настройка полностью удаляет изменения VIP и DNS. И хотя мы вводим больше компонентов, мы можем отделить компоненты и упростить задачу, а также иметь возможность использовать надежные и стабильные решения. Далее следует разбивка.
Нормальный поток
В обычный день приложения подключаются к узлам записи через GLB / HAProxy.
Приложения никогда не осведомлены о подлинности мастера. Как и раньше, они используют имя. Например, основным для кластера1 будет mysql-writer-1.github.net. Однако в нашей текущей настройке это имя разрешено для IP-адреса anycast.
С anycast имя разрешается для одного и того же IP-адреса повсюду, но трафик маршрутизируется по-разному на основе местоположения клиента. В частности, в каждом из наших центров обработки данных имеется GLB, наш высокодоступный балансировщик нагрузки, развернутый на нескольких блочных элементах. Трафик на mysql-writer-1.github.net всегда направляется в кластер GLB локального центра обработки данных. Таким образом, все клиенты обслуживаются локальными прокси.
Мы запускаем GLB поверх HAProxy. Наш HAProxy имеет пулы записей: один пул на каждый кластер MySQL, где каждый пул имеет ровно один бэкэнд-сервер: мастер кластера. Все поля GLB / HAProxy во всех DC-серверах имеют одинаковые пулы, и все они указывают на то же самое бэкэнд-серверы в этих пулах. Таким образом, если приложение хочет писать в mysql-writer-1.github.net, не важно, к какому серверу GLB он подключается. Он всегда будет перенаправляться на главный кластер1.
Что касается приложений, открытие заканчивается в GLB, и нет необходимости в повторном открытии. Все на GLB необходимо направлять трафик в нужное место назначения.
Как GLB узнает, какие серверы будут перечисляться как backend, и как мы будем распространять изменения в GLB?
Открытие через Consul
Consul хорошо известен как решение для открытия служб, а также предлагает службы DNS. Однако в нашем решении мы используем его как высокодоступный магазин ключей (KV).
В магазине KV Consul мы записываем идентификаторы кластерных мастеров. Для каждого кластера есть набор записей KV, указывающих мастер-файл fqdn, порт, ipv4, ipv6.
Каждый узел GLB / HAProxy запускает consul-template - службу, которая слушает изменения данных Consul (в нашем случае: изменения в данных кластеров). consul-template создает действительный файл конфигурации и может перезагрузить HAProxy при изменении конфигурации.
Таким образом, изменение в Consul подлинности мастера наблюдается каждым блоком GLB / HAProxy, который затем перенастраивается, устанавливает новый мастер как единый объект в бэкэнд-пуле кластера и перезагружается, чтобы отразить эти изменения.
В GitHub у нас есть настройка Consul в каждом центре обработки данных, и каждая установка очень доступна. Однако эти установки не зависят друг от друга. Они не реплицируются между собой и не передают никаких данных.
Как Consul рассказывает об изменениях и как распределяется информация по перекрестному DC?
orchestrator/raft
Мы запускаем настройку orchestrator/raft: узлы оркестратора обмениваются друг с другом по контенту на raft. У нас есть один или два узла оркестратора для каждого центра обработки данных.
Orchestrator загружается с обнаружением отказа, с переходом на MySQL с ошибкой и с сообщением об изменении мастера в Consul. Отказоустойчивость управляется единственным лидирующим узлом лидерства orchestrator/raft, но изменение, новости о том, что кластер теперь имеет нового мастера, распространяется на все узлы orchestrator через механизм raft.
Поскольку узлы оркестратора получают новости о главном изменении, каждый из них связывается со своими локальными настройками Consul: каждый из них вызывает запись KV. DC с более чем одним представителем оркестратора будет иметь несколько (идентичных) записей для Consul.
Объединяя поток
В сценарии сбоя мастера:
- Узлы оркестратора обнаруживают сбои.
- Лидер orchestrator/raft начинает восстановление. Создается новый мастер.
- orchestrator/raft объявляет об изменении мастера для всех узлов кластера.
- Каждый участник orchestrator/raft получает уведомление об изменении лидера. Каждый из них обновляет локальное хранилище KV Consul с подлинностью нового мастера.
- В каждом GLB/HAProxy работает консул-шаблон, который наблюдает за изменением в хранилище KV Consul и реконфигурирует и перезагружает HAProxy.
- Клиентский трафик перенаправляется на новый мастер.
Существует четкое владение обязанностями по каждому компоненту, и весь дизайн расцеплен и упрощен. Orchestrator не знает о балансировщиках нагрузки. Consul не нужно знать, откуда взялась информация. Прокси только заботятся о Consul. Клиенты заботятся только о прокси.
Более того:
- Нет никаких изменений DNS для распространения.
- Нет TTL.
- Поток не нуждается в сотрудничестве прежнего мастера. Это в значительной степени игнорируется.
Дополнительные детали
Для обеспечения безопасности потока мы также имеем следующее:
- HAProxy настроен с очень короткой остановкой. Когда он перезагружается с новым бэкэнд-сервером в пуле записей, он автоматически прекращает любые существующие соединения со старым мастером. С жесткой остановкой - после того, как мы даже не требуем сотрудничества со стороны клиентов, и это смягчает сценарий split-brain. Примечательно, что это не герметично, и прошло некоторое время, прежде чем мы уничтожим старые связи. Но есть момент времени, после которого мы чувствуем себя комфортно и не ожидаем неприятных сюрпризов.
- Мы не требуем, чтобы Consul всегда был доступен. Фактически, нам нужно, чтобы он был доступен во время переключения. Если Consul не работает, GLB продолжает работать с последними известными значениями и не делает кардинальных шагов.
- GLB настроен на проверку подлинности вновь созданного мастера. Подобно нашим пулам MySQL, поддерживающим контекст, проверка выполняется на сервере backend, чтобы убедиться, что он действительно является узлом записи. Если нам удастся удалить подлинность мастера в Consul, - не проблема; пустая запись игнорируется. Если мы ошибочно напишем имя немастерного сервера в Consul, - не проблема; GLB откажется обновить его и продолжить работу с последним известным состоянием.
Мы также решаем проблемы и преследуем цели HA в следующих разделах.
Обнаружение отказа orchestrator/raft
Orchestrator использует целостный подход к обнаружению отказа, и поэтому он очень надежен. Мы не наблюдаем ложных срабатываний: у нас нет преждевременных отказов и, следовательно, они не страдают от ненужного времени простоя.
orchestrator/raft дополнительно решает проблему полной изоляции сети постоянного тока (например, DC-ограждение). Изоляция сети постоянного тока может вызвать путаницу: серверы внутри этого DC могут разговаривать друг с другом. Разве это они, которые изолированы от других DC, или это другие DC, которые изолированы от сети?
В настройке orchestrator/raft это тот, который запускает отказоустойчивость. Лидер - это узел, который получает поддержку большинства группы (кворум). Наше развертывание узла оркестратора таково, что ни один центр обработки данных не делает большинство, а любые n-1 делает DC.
В случае полной изоляции сети постоянного тока узлы оркестра в этом контроллере постоянного тока отсоединяются от своих одноранговых узлов в других контроллерах домена. В результате узлы orchestrator в изолированном DC не могут быть лидерами кластера raft. Если любой такой узел оказался лидером, он уходит. Новый лидер будет назначен от любого другого DC. Этот лидер будет иметь поддержку всех других DC, которые способны общаться между собой.
Таким образом, узлом оркестратора, который вызывает снимки, будет тот, который находится за пределами изолированного центра данных. Если в изолированном DC есть мастер, оркестратор инициирует восстановление после сбоя, чтобы заменить его сервером в одном из доступных контроллеров домена. Мы уменьшаем изоляцию постоянного тока, делегируя принятие решения к кворуму в неизолированных DC.
Более быстрое объявление
Суммарное время отключения может быть дополнительно уменьшено путем более раннего объявления об изменениях мастера. Как это можно достичь?
Когда оркестратор начинает переход на другой ресурс, он наблюдает за количеством доступных серверов. Понимая правила репликации и соблюдая советы и ограничения, он может принять обоснованное решение о лучшем курсе действий.
Он может признать, что сервер, доступный для продвижения, также является идеальным кандидатом, так что:
- Нельзя предотвратить продвижение сервера (и, возможно, пользователь намекнул, что такой сервер является предпочтительным для продвижения), и
- Ожидается, что сервер сможет взять все свои родственные узлы в качестве реплик.
В таком случае оркестратор начинает сначала устанавливать сервер как записываемый и сразу объявляет продвижение сервера (пишет в нашем случае Consul KV), даже если асинхронно начинает исправлять дерево репликации - операция, которая обычно занимает несколько больше секунд.
Вероятно, к тому времени, когда наши серверы GLB будут полностью перезагружены, дерево репликации уже будет целым, но это строго не требуется. Сервер в хорошем состоянии, чтобы получать записи!
Полусинхронная репликация
В полусинхронной репликации MySQL мастер не признает транзакцию, пока изменение, как известно, не отправлено на одну или несколько реплик. Он обеспечивает способ обеспечения отказоустойчивости без потерь: любые изменения, применяемые к мастеру, либо применяются, либо ожидаются для применения на одной из реплик.
Согласованность сопряжена со стоимостью: риском доступности. Если никакая реплика не подтвердит получение изменений, мастер заблокирует и запись будет остановлена. К счастью, существует конфигурация тайм-аута, после которой мастер может вернуться в режим асинхронной репликации, что делает запись доступной снова.
Мы установили наш тайм-аут с достаточно низким значением: 500 мс. Этого более чем достаточно, чтобы отправлять изменения с мастера на локальные реплики постоянного тока и, как правило, также на удаленные DC. С этим тайм-аутом мы наблюдаем идеальное поведение полусинхронизации (без возврата к асинхронной репликации), а также чувствуем себя комфортно с очень коротким периодом блокировки в случае отказа подтверждения.
Мы включаем полусинхронизацию локальных реплик DC, и в случае утраты мастера мы ожидаем (хотя и не строго соблюдаем) переход на другой ресурс без потерь. Отказоустойчивый переход при полном сбое DC является дорогостоящим, и мы этого не ожидаем.
Во время экспериментов с тайм-аутом с половинной синхронизацией мы также наблюдали выгодное для нас поведение: мы можем влиять на личность идеального кандидата в случае неудачи мастера. Включив полусинхронизацию на назначенных серверах и отметив их как кандидатов, мы можем сократить общее время отключения, повлияв на результат отказа. В наших экспериментах мы наблюдаем, что мы, как правило, заканчиваем идеальными кандидатами и, следовательно, запускаем быстрые объявления.
Внедрение пульсации
Вместо того, чтобы управлять запуском / выключением службы pt-heartbeat на продвигаемых /смещенных мастерах, мы решили использовать ее везде в любое время. Это потребовало некоторого исправления, чтобы сделать pt-heartbeat удобным с серверами, либо изменяя их состояние read_only туда и обратно или полностью осуществить сбой.
В нашей текущей настройке службы pt-heartbeat работают на мастерах и на репликах. На мастерах они генерируют события пульсации. В репликах они идентифицируют, что серверы доступны только для чтения и регулярно перепроверяют их статус. Как только сервер продвигается как master, pt-heartbeat на этом сервере идентифицирует сервер как записываемый и начинает вводить события пульсации.
Делегирование полномочий оркестратора
Мы дополнительно делегировали оркестратору:
- Внедрение Pseudo-GTID
- Установку продвигаемого мастера как перезаписываемого, очистка его состояния репликации и
- По возможности установку старого мастера как read_only.
На всех новых мастерах это уменьшает трение. Очевидно, что мастер, который только начал продвигаться, будет живым и доступным, иначе мы не будем его продвигать. Поэтому имеет смысл дать возможность оркестратору применить изменения непосредственно к продвигаемому мастеру.
Ограничения и недостатки
Прокси-уровень заставляет приложения не осознавать подлинность мастера, но также маскирует идентификаторы приложений от мастера. Все мастера видят соединения, исходящие из прокси-уровня, и мы теряем информацию о реальном источнике соединения.
По мере того как работают распределенные системы, мы по-прежнему остаемся с необработанными сценариями.
Примечательно, что в сценарии изоляции центра обработки данных и при условии, что мастер находится в изолированном дата-центре, приложения в этом DC все еще могут делать записи мастеру. Это может привести к несогласованности состояния после восстановления сети. Мы работаем над тем, чтобы смягчить этот сценарий split-brain, внедряя надежный STONITH из очень изолированного DC. Как и прежде, пройдет некоторое время перед устранением мастера, и может быть короткий период split-brain. Эксплуатационные затраты на предотвращение split-brain в целом очень высоки.
Существуют и другие сценарии: отключение Consul во время перехода на другой ресурс; частичная изоляция DC и другие. Мы понимаем, что с распределенными системами такого рода невозможно закрыть все лазейки, поэтому мы сосредоточимся на наиболее важных случаях.
Результаты
Наша настройка Orchestrator/GLB/Consul дает нам:
- Надежное обнаружение отказа,
- Независимые восстановления дата-центров
- Восстановления без потерь
- Поддержка изоляции сети DC
- Cмягчение split-brain (больше в работах)
- Никакой зависимости от взаимодействия,
- В большинстве случаев от 10 до 13 секунд общего времени отключения.
- Мы видим до 20 секунд общего времени отключения в менее частых случаях и до 25 секунд в крайних случаях.
Вывод
Парадигма оркестровки / прокси/службы-обнаружения использует хорошо известные и надежные компоненты в расцепленной архитектуре, что упрощает развертывание, работу и наблюдение и здесь каждый компонент может независимо масштабироваться вверх или вниз. Мы продолжаем добиваться улучшений, поскольку мы постоянно тестируем нашу установку.
Инженерная служба Github