Структурированная потоковая передача с помощью Azure Databricks в Power BI & Cosmos DB
В этом блоге мы обсудим концепцию Structured Streaming и то, как путь проникновения данных может быть построен с использованием Azure Databricks для обеспечения потоковой передачи данных в режиме реального времени. Мы коснемся некоторых возможностей анализа, которые могут быть вызваны непосредственно в Databricks с использованием API текстовой аналитики, а также обсудим, как Databricks можно напрямую подключать к Power BI для дальнейшего анализа и отчетности. В качестве заключительного шага мы рассмотрим, как потоковые данные могут быть отправлены из Databricks в базу данных Cosmos DB в качестве постоянного хранилища.
Структурированная потоковая передача - это механизм обработки потока, который позволяет использовать экспресс-вычисления для потоковой передачи данных (например, канал Twitter). В этом смысле он очень похож на способ, которым выполняется пакетное вычисление на статическом наборе данных. Вычисление выполняется инкрементально с помощью механизма Spark SQL, который обновляет результат как непрерывный процесс по потоку данных.
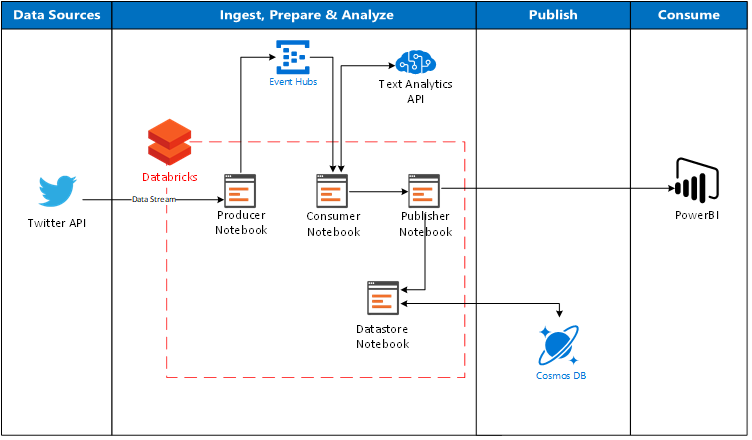
Вышеупомянутая архитектура иллюстрирует возможный поток на то, как Databricks можно использовать напрямую в качестве пути получения для передачи данных из Twitter (через концентраторы событий, чтобы действовать как буфер), вызвать Text Analytics API в Cognitive Services для применения интеллекта к данным, а затем наконец, отправить данные непосредственно в Power BI и Cosmos DB.
Концепция структурированной потоковой передачи
Все данные, поступающие из потока данных, рассматриваются как неограниченная входная таблица. Для каждой новой информации в потоке данных новая строка добавляется к неограниченной входной таблице. Весь вход не сохраняется, но конечный результат эквивалентен сохранению всего ввода и выполнению пакетного задания.
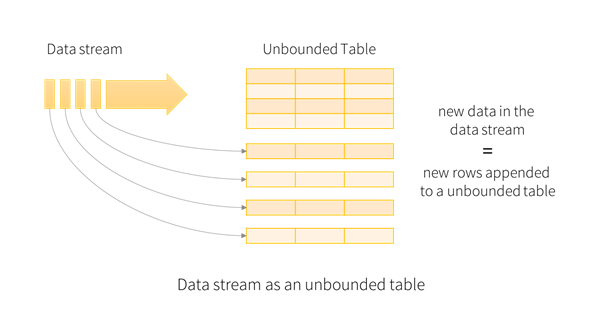
Таблица ввода позволяет нам определять запрос сам по себе, как если бы это была статическая таблица, которая будет вычислять окончательную таблицу результатов, написанную на выходе. Этот пакетный запрос автоматически преобразуется Spark в план выполнения потоковой передачи через процесс, называемый инкрементным выполнением.
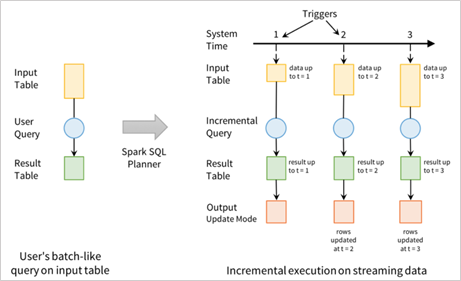
Инкрементальное выполнение - это то, где Spark изначально рассчитывает состояние, необходимое для обновления результата каждый раз, когда приходит запись. Мы можем использовать встроенные триггеры, чтобы указать, когда обновлять результаты. Для каждого запускающего триггера Spark ищет новые данные в таблице ввода и обновляет результат поэтапно.
Запросы в таблице ввода будут генерировать таблицу результатов. Для каждого интервала триггера (например, каждые три секунды) к таблице ввода добавляются новые строки, которые в процессе инкрементного выполнения обновляют таблицу результатов. Каждый раз, когда таблица результатов обновляется, измененные результаты записываются как результат.
Результат определяет, что записывается на внешнее хранилище, независимо от того, находится ли это непосредственно в файловой системе Databricks или в нашем примере CosmosDB.
Чтобы реализовать это в Azure Databricks, функция входящего потока вызывается для инициирования StreamingDataFrame на основе заданного ввода (в этом примере данные Twitter). Затем поток обрабатывается и записывается как формат паркета во внутреннее хранилище файлов Databricks, как показано в приведенном ниже фрагменте кода:
val streamingDataFrame = incomingStream.selectExpr("cast (body as string) AS Content")
.withColumn("body", toSentiment(%code%nbsp;"Content"))
import org.apache.spark.sql.streaming.Trigger.ProcessingTime
val result = streamingDataFrame
.writeStream.format("parquet")
.option("path", "/mnt/Data")
.option("checkpointLocation", "/mnt/sample/check")
.start()
Монтирование файловых систем в Databricks (CosmosDB)
Несколько различных файловых систем могут быть установлены непосредственно внутри Databricks, таких как Blob Storage, Data Lake Store и даже SQL Data Warehouse. В этом блоге мы рассмотрим возможности подключения между Databricks и DB Cosmos.
Быстрая связь между Apache Spark и Azure Cosmos DB ускоряет способность решать проблемы быстрого движения Data Sciences, где данные могут быстро сохраняться и извлекаться с использованием Azure Cosmos DB. С соединителем Spark to Cosmos DB можно разрешать сценарии IoT, обновлять столбцы при аналитике, отбрасывать предикатную фильтрацию и выполнять расширенную аналитику против быстрых изменений данных в хранилище управляемых документов с реплицированием с гарантированными SLA для обеспечения согласованности, доступности, низкой задержкой и пропускной способностью.
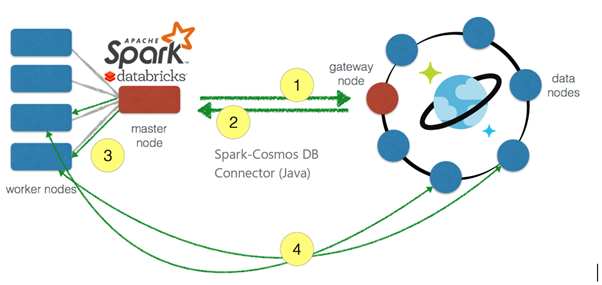
- Внутри Databricks соединение производится с ведущего узла Spark на узел шлюза Cosmos DB для получения информации о разделе из Cosmos.
- Информация о разделе переводится обратно на главный узел Spark и распределяется между рабочими узлами.
- Эта информация переводится обратно в Spark и распределяется между рабочими узлами.
- Это позволяет рабочим узлам Spark взаимодействовать непосредственно с разделами базы данных Cosmos при поступлении запроса. Рабочие узлы могут извлекать данные, которые необходимы, и возвращать данные обратно в разделы Spark внутри рабочих узлов Spark.
Обмен данными между Spark и Cosmos DB происходит значительно быстрее, поскольку движение данных происходит между рабочими узлами Spark и узлами данных Cosmos DB.
Используя разъем Azure Cosmos DB Spark (в настоящее время в режиме предварительного просмотра), можно напрямую подключиться к учетной записи хранилища Cosmos DB из Databricks, позволяя базе данных Cosmos DB выступать в качестве источника входного сигнала или выходного приемника для заданий Spark, как показано в фрагменте кода ниже:
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
val writeConfig = Config(Map("Endpoint, MasterKey, Database, PreferredRegions, Collection, WritingBatchSize"))
import org.apache.spark.sql.SaveMode
sentimentdata.write.mode(SaveMode.Overwrite).cosmosDB(writeConfig)
Подключение Databricks к PowerBI
Microsoft Power BI - это служба бизнес-аналитики, которая обеспечивает интерактивную визуализацию с возможностями самообслуживания бизнес-аналитики, позволяя конечным пользователям самостоятельно создавать отчеты и информационные панели, не завися от сотрудников информационных технологий или администраторов баз данных.
Azure Databricks можно использовать в качестве прямого источника данных с помощью Power BI, что позволяет повысить производительность и преимущества технологии Azure Databricks за счет ученых по данным и инженеров-разработчиков данных для всех бизнес-пользователей.
Power BI Desktop можно подключить непосредственно к кластеру Azure Databricks с помощью встроенного разъема Spark (в настоящее время в режиме предварительного просмотра). Коннектор позволяет использовать DirectQuery для обработки выгрузки для Databricks, что отлично, когда у вас большой объем данных, которые вы не хотите загружать в Power BI, или когда вы хотите выполнить почти анализ в реальном времени, как обсуждалось в этом разделе поста.
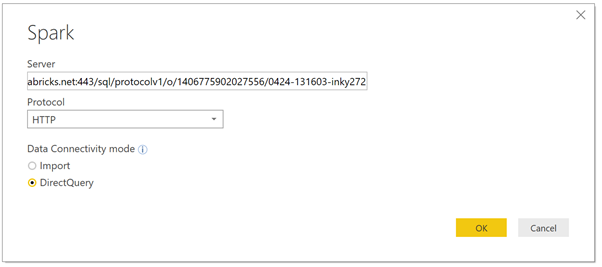
Этот разъем использует соединение JDBC/ODBC через DirectQuery, позволяя использовать живое соединение в установленном хранилище файлов для потоковых данных, поступающих через Databricks. Из Databricks мы можем установить расписание (например, каждые 5 секунд) для записи потоковых данных в хранилище файлов, а из Power BI выводить это регулярно, чтобы получить поток данных, близкий к реальному времени.
Внутри Power BI различные аналитики и визуализации могут быть применены к потоковому набору данных, оживляя его!