Создание среды разработки и производства для машинного обучения в Power BI
В большинстве проектов необходимо изолировать среду разработки и производства. Настройка этих сред помогает нам поставлять более надежный продукт нашим клиентам.
Проектам машинного обучения также необходима среда разработки, тестирования и производства.
В этом посте мы покажем вам, как можно сделать это в среде Power BI с помощью языка M и Power Query.
Что подразумевает разработка в проектах машинного обучения?
Согласно приведенной ниже диаграмме (Data Science LifeCycle), после понимания бизнеса нам нужно получить данные и выполнить моделирование. Мы можем поместить этап сбора данных и моделирования в среду разработки. Заключительный этап, который является развертыванием модели, должен быть включен в среду разработки.
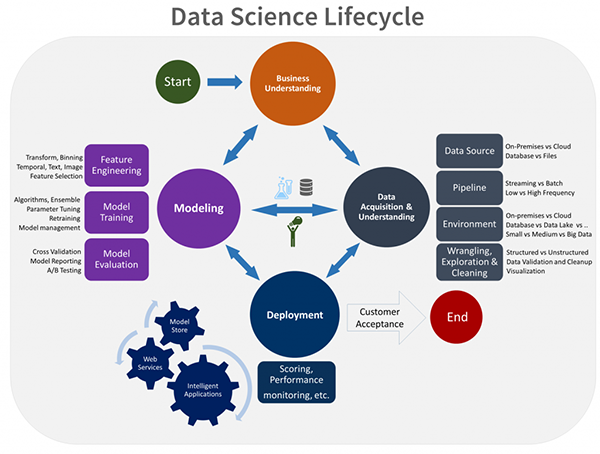
Рисунок 1. Жизненный цикл обработки данных, предложенный Microsoft Research
Чтобы упростить его, нам нужна среда для обучения и тестирования модели и еще одна среда для развертывания модели, чтобы конечный пользователь мог работать и делать прогноз.
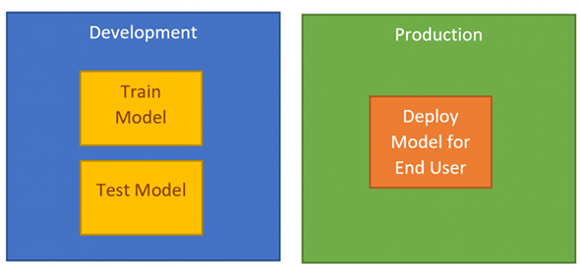
Рисунок 2. Уникальная среда для машинного обучения
Уникальная среда в Power BI-Power Query
Мы собираемся запустить прогностический анализ для проблемы классификации в Power Query, используя алгоритм дерева решений (rpart для этого примера). Напомним, что Power BI - это самообслуживающиеся инструменты BI. Power BI используется для визуализации данных, интеграции данных и моделирования.
Существует возможность запуска R-кодов внутри Power BI / Power Query. Активизируем запрос с помощью « Edit Queries».
Рисунок 3. Редактирование запросов Windows
В Power Query выберите New Source-> Text/CSV, затем перетащите файл (titanic.csv). Набор данных «Титаник» похож на Hello world! для науки о данных. Это бесплатный набор данных, который вы можете загрузить с https://www.kaggle.com/fossouodonald/titaniccsv/data. Просто загрузите набор данных. После загрузки вы можете видеть ниже окна
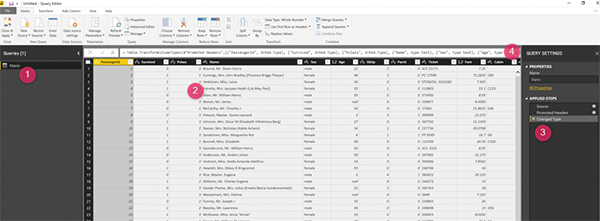
Рисунок 4. Среда Power Query после загрузки набора данных Titanic
Как видно на рисунке 4, в номере 1 у нас есть имя набора данных в группе запросов. Вторая область - это номер 2 на рисунке 4, который показывает столбец данных и атрибуты для Titanic. В номере 3 на приведенном выше рисунке вы можете увидеть шаги для получения данных из ресурса, изменяющих тип столбца (эти шаги автоматически применяются). Наконец, в номере 4 есть редактор кода для языка M, который расширяет возможности для очистки и подготовки для нас данных.
Перейдите на вкладку «Transform», а затем в Run R scripts
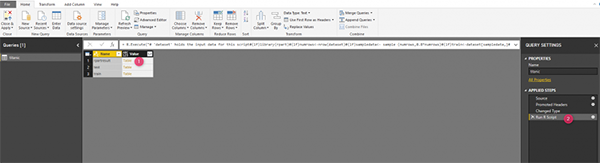
Рисунок 6. Запуск R-скриптов.
Вы должны увидеть редактор R-скриптов, который поможет нам запустить наши R-коды.
Учебная среда
Мы собираемся сделать прогноз, выживет ли человек с определенным возрастом, полу, пассажирским классом. Чтобы решить эту задачу, можно воспользоваться приведенным ниже кодом:
library(rpart)
rpart - это знаменитый пакет R для дерева решений. Мы уже установили этот пакет в Rstudio, а затем здесь мы просто ссылаемся на него.
Следующим шагом мы собираемся указать набор учебных и тестовых данных. С этой целью сперва мы вычисляем количество строк в наборе данных, используя следующую команду:
numrows<-nrow(dataset)
На следующем этапе мы возьмем 80% данных на обучение и 20% на тестирование.
sampledata<- sample (numrows,0.8*numrows)
train<-dataset[sampledata,]
test<-dataset[-sampledata,]
Теперь набор данных для обучения готов. Вслед за этим мы используем функцию rpart для создания модели дерева решений. первый параметр - это формула для создания модели g (Survived ~.). второй - набор учебных материалов, а последний - метод. Метод для этого предсказания - это классификация, поэтому для последних параметров мы используем «class».
DT<-rpart(Survived~.,data=train,method=”class”)
Наконец, мы используем команду прогнозирования, чтобы применить тестовый набор данных к нашей созданной модели.
prediction<-predict (DT,test)
Чтобы показать результат предсказания, мы создали кадр данных из результата предсказания и набора тестовых данных.
rpartresult<-data.frame(prediction,test)
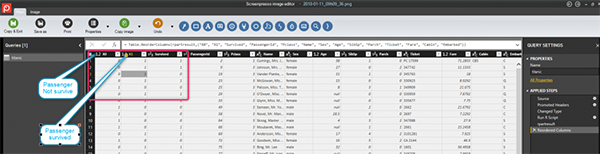
Наконец, изучив результат, мы получаем следующую таблицу, где первая колонка для выживших, вторая - для не выживших.
Учебная среда
Мы собираемся создать учебную среду. В результате, другие пользователи могут применять rpart для классификации или регрессии в своих данных.
Шаг 1. Создание функции
На первом этапе мы собираемся кликнуть правой кнопкой мыши по запросу titanic, чтобы создать функцию.
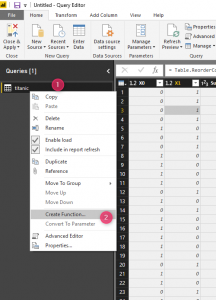
Затем назначьте имя функции, например, "rpartFunction"
Как вы можете видеть на рисунке ниже, мы создаем функцию, которая до сих пор не имеет аргументов. Чтобы передать аргументы этой функции, нам нужно нажать Advanced Editor (номер 3)
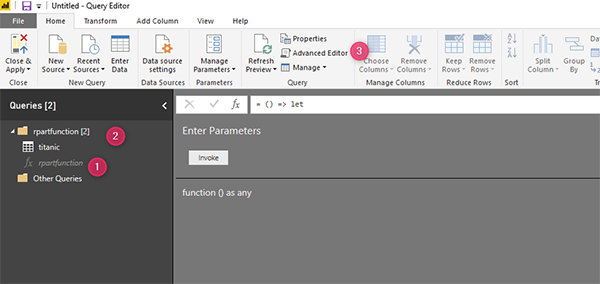
Поэтому расширенный редактор Power Query - это место, где мы можем писать M-коды.
Изменим первые три строки следующим образом:

замените первый код трех строк на следующие коды
(#”Source Table” as table,#”Prediction Column”as text,Split as number,Method as text) as table=>
let
Source = #”Source Table”,
Изменим код, как показано ниже. Как видно на рисунке, первая строка определяет входные данные для нашей функции.
1- source table - таблица для обучения
2- Prediction Column - какие атрибуты мы собираемся предсказать
3-Split - сколько данных должно уйти на обучение и сколько на тестирование
4-Method - прогноз для классификации или регрессии
Также в строке 6 мы можем видеть тег для «RunRscripts», и вы можете видеть код, уже написанный в редакторе сценариев R.

Теперь нам нужно удалить все шаги перед запуском R-скриптов и поместить параметры внутри R-кодов.
Теперь нам требуется сделать еще несколько следующих изменений в коде:
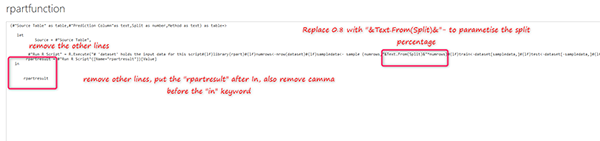
На рисунке показано, что мы удаляем другие строки до запуска r скриптов. Затем мы начинаем заменять некоторые переменные. Например, на приведенном выше рисунке мы заменяем 0,8 «&Text.From (Split)&».
Нам нужно подставить другую переменную, например, Survived, Method и источник данных.

Как вы можете видеть на приведенном выше рисунке, в функции rpart мы заменили “Survived“ на: “&#” Prediction Column”&”, а также заменим “class” на ”&Method&”. Наконец, в конце строки для набора данных мы заменим его “Source”.
теперь у нас есть четыре параметра, которые были заменены в коде.
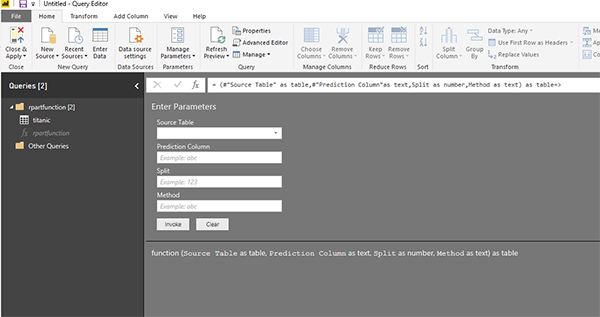
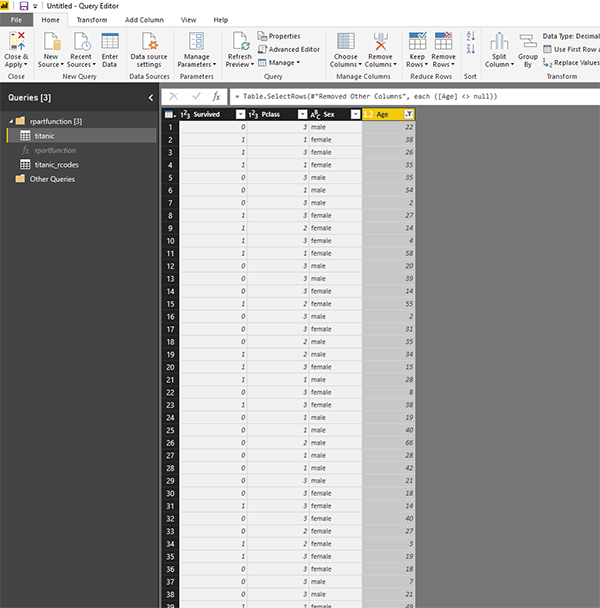
Как вы можете видеть выше, теперь у нас есть четыре основных параметра. Для запуска кода нам просто нужно предоставить данные. Создадим новый набор данных для titanic, который имеет только четыре основных столбца, а все нулевые значения удалены.
Теперь вызовем функцию с условием:
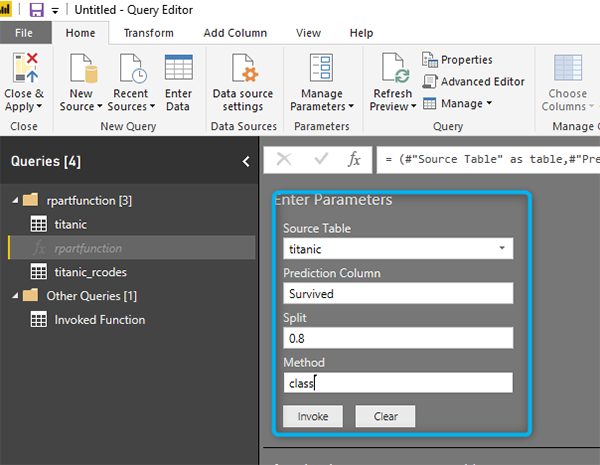
После вызова кода результат предсказания будет показан как новый запрос.
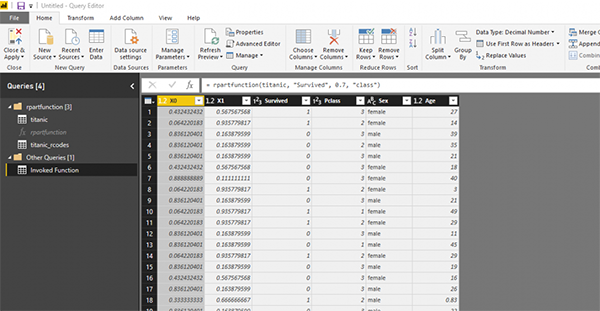
Теперь мы собираемся импортировать новый набор данных для лечения рака и применять функцию rpart к ней для прогнозирования того, что диагноз пациента становится доброкачественным или злокачественным.
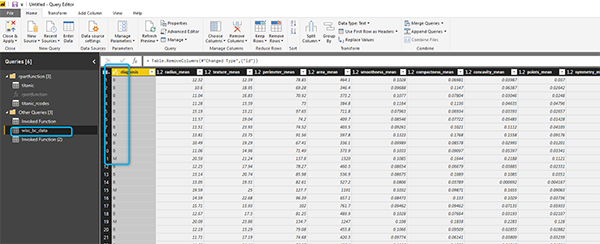
Для этого сообщения мы не нормализовали данные для данных о раке. Но есть необходимость в подготовке некоторых данных. Мы представили данные для вызова функции классификации rpart, как показано ниже
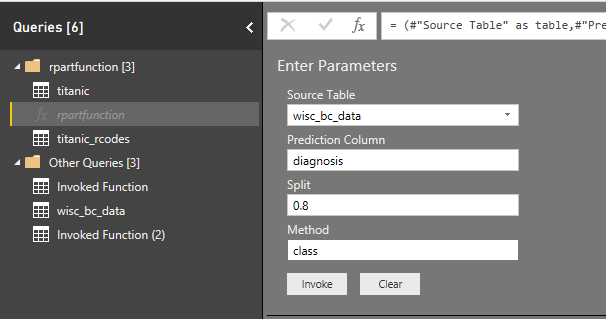
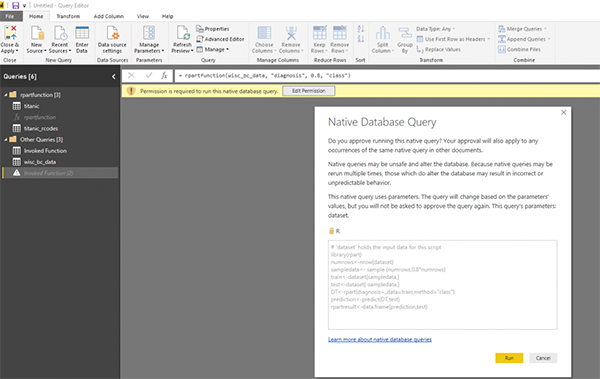
После вызова функции он получает разрешение на запуск запроса и отображение r-скриптов, которые будут запущены.
После запуска кода получаем следующий результат:
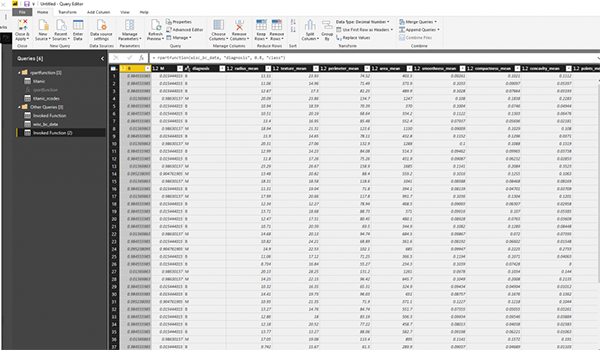
Теперь в другом упражнении мы используем rpart для предсказания регрессии. Конкретный пример в Post. Мы собираемся предсказать прочность бетона.
Импортируем набор данных для бетона.
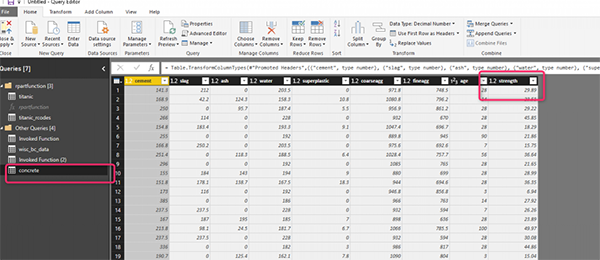
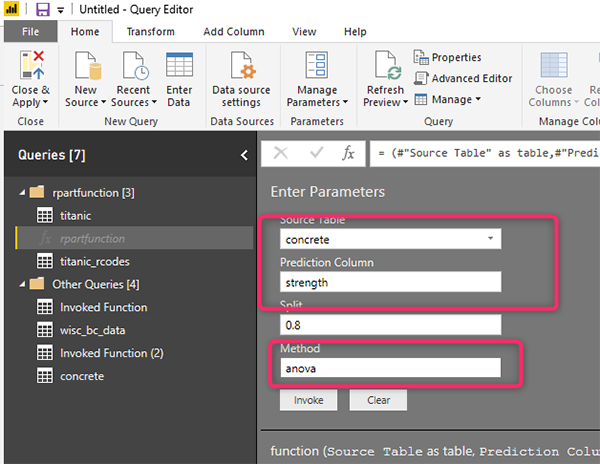
Теперь вызовем функцию для параметров. Как вы можете видеть на рисунке ниже, набор данных - «concrete», столбец прогноза - «strength», метод на этот раз «anova» вместо “class”.
После вызова функции предсказание прочности бетона было показано в отдельном запросе, как показано ниже
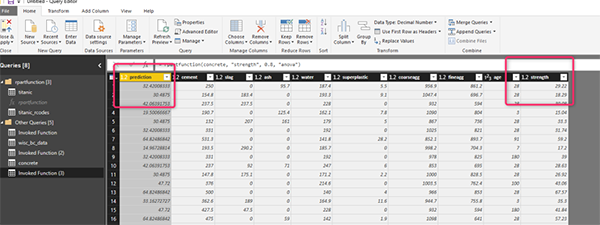
В этом сообщении вы видите, как мы можем параметризовать учебную модель в Power BI. Далее мы покажем вам, как мы можем создать другую группу для тестирования и обучения.