Основы использования INCLUDE
Недавно в одном посте обсуждалась производительность таблицы без ключей или индексов. Это рецепт низкой производительности в запросах, если эта таблица становится большой. Сегодня мы покажем, как индекс может изменить производительность запроса. Во многих случаях запрос является запросом диапазона, который ищет серию записей между двумя датами. Это распространенный тип запроса, который будет использоваться для этого типа таблицы. Мы будем использовать его как диапазон от начальной даты до конечной даты, как открытый диапазон.
Некоторые озадачены или удивлены тем, что фраза INCLUDE является частью индекса. Эта статья призвана показать несколько основ того, как предложение INCLUDE влияет на запросы и индексацию.
ПРИМЕЧАНИЕ: пожалуйста, поймите, что индексация - сложная тема, и мы не хотим ни избегать новых индексов, ни добавлять индексы для каждой ситуации. Мы хотим ограничить количество индексов для занятых таблиц, поэтому разумно решите, следует ли добавлять в таблицу индекс, который вы тестируете.
Настройка таблицы аудита
В этом случае таблица представляла собой таблицу аудита с несколькими столбцами. Чтобы упростить вещи, мы создадим узкую версию этой таблицы.
CREATE TABLE AuditLog
( AuditKey INT IDENTITY(1,1) NOT NULL CONSTRAINT AuditLogPK PRIMARY KEY
, SourceTable VARCHAR(128) NOT NULL
, UserTable VARCHAR(128) NOT NULL
, AuditTimestamp DATETIME2 NOT NULL
, AuditMessage VARCHAR(5000) NOT NULL
, ReferenceKey VARCHAR(100) NOT NULL
);
GO
Мы заполним это 100 000 строками, используя SQL Data Generator. Это быстрый способ случайного добавления некоторых данных, которые помогут проверить производительность. После загрузки таблицы выполним запрос, который ищет записи на основе даты.
Основной запрос
Наша таблица просто имеет базовый кластерный индекс для первичного ключа. Это хорошо, но в этом случае это не будет полезно. Один общий запрос, который часто запускают люди, основан на дате, поэтому давайте создадим индекс для поддержки этого:
CREATE INDEX AuditLog_IDX_Timestamp ON dbo.AuditLog (AuditTimestamp);
Теперь мы можем выполнить этот основной запрос.
SELECT al.SourceTable,
al.ReferenceKey,
al.AuditTimestamp
FROM dbo.AuditLog AS al
WHERE al.AuditTimestamp > '2019-01-01';
GO
Если мы запустим это, то получим 2,576 строк в нашем тестовом наборе. Не малое количество, но и не огромное. Если мы зафиксируем план выполнения, то увидим следующее:
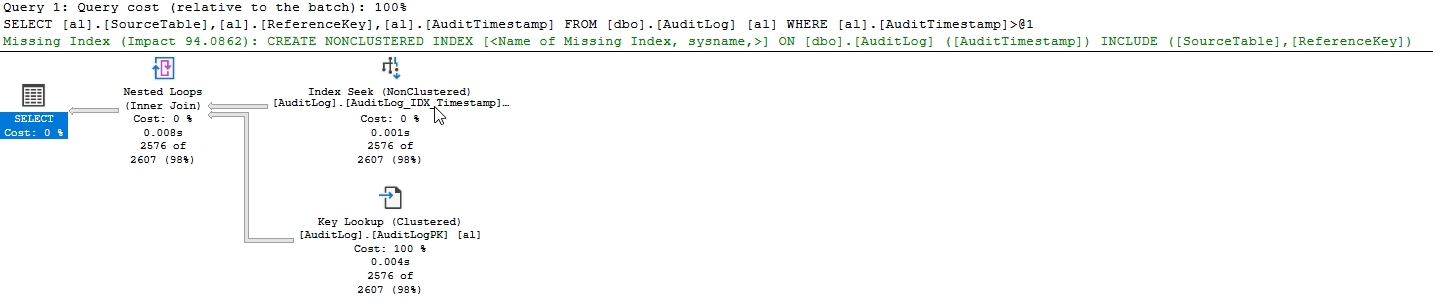
Неплохо, мы получаем запрос, и так как нам нужно больше, чем просто ключевой столбец, мы также получим поиск. Из STATISTICS TIME и IO мы также видим:
(2576 rows affected)
Table 'AuditLog'. Scan count 1, logical reads 7907, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row affected)
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 125 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Производительность здесь не плохая. Этого мы и ожидаем с хорошим индексом, который соответствует предикату запроса, который мы используем. Многие из нас остановились бы здесь с регулировкой и думали, что это здорово. Особенно в качестве предварительного индекса, у нас было более 40000 логических чтений и сканирование кластерного индекса.
Посмотрим, сможем ли мы улучшить это.
Подсказка
На самом деле есть подсказка в плане выполнения, показанном выше. Отсутствующий указатель индекса показывает, где SQL Server считает, что этот запрос может получить выгоду от INCLUDE, и он получает. Давайте попробуем это. Сначала мы удаляем существующий индекс, а затем воссоздаем его, но добавим предложение INCLUDE.
DROP INDEX AuditLog_IDX_Timestamp ON dbo.AuditLog
GO
CREATE INDEX AuditLog_IDX_Timestamp ON dbo.AuditLog (AuditTimestamp)
INCLUDE (SourceTable, ReferenceKey)
Теперь давайте снова запустим запрос. На этот раз мы получаем другой план выполнения:

Это намного лучше, так как показывает минимальный поиск строк. Мы также видим, что для чтения используется меньше ресурсов: 19 логических операций вместо 7 907.
(2576 rows affected)
Table 'AuditLog'. Scan count 1, logical reads 19, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 73 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Это улучшение, которое вы можете получить с помощью INCLUDE.
Использование INCLUDE
Условие INCLUDE в индексе - это возможность добавить в индекс другие столбцы данных. Однако эти столбцы не используются в условии WHERE как возможные значения предикатов. Они добавляются на конечный уровень индекса и полезны для удаления поиска ключа, который мы получили в первом плане выполнения.
Есть две части запроса, которые могут повлиять на производительность. Во-первых, как быстро мы можем найти нужные нам строки, поэтому мы создаем индексы. В этом случае оба протестированных нами индекса имели столбец AuditTimestamp в качестве ключевого столбца. Это позволило механизму выполнения запроса быстро найти строки, которые удовлетворяли бы запросу.
Вторая часть запроса, которая влияет на производительность, - это данные из тех строк, которые необходимо вернуть. Если данные находятся в индексе, таком как AuditTimestamp, то это очень низкая стоимость возврата. Однако, если данные отсутствуют в индексе, ядро должно перейти к кластерному индексу или динамической памяти, чтобы получить данные. Это одна из причин, по которой SELECT * является ужасной концепцией в рабочем коде.
С помощью условия INCLUDE мы можем добавить эти столбцы к индексу и разрешить охват запроса со всеми данными, необходимыми для запроса, включенными в индекс.
Выбор столбцов, которые следует включить, должен быть сделан осторожно, с учетом баланса рабочей нагрузки в вашем экземпляре. Каждый добавленный столбец увеличивает ширину индекса и, следовательно, размер. Это уменьшает преимущество некластеризованного индекса над кластеризованным индексом, а также увеличивает количество ресурсов, которые поддерживают индекс при каждой вставке / обновлении / удалении. Дополнительные столбцы также увеличивают количество операций чтения, необходимых для использования индекса во всех запросах.
Резюме
Использование предложения INCLUDE поможет вам ускорить выполнение некоторых распространенных запросов, поскольку движку не требуется доступ к кластерному индексу или куче дополнительных данных. Когда столбцы часто используются в списке столбцов SELECT, но не в предикатах, добавление их в качестве INCLUDE может быть полезным для уменьшения необходимости добавления поиска в план выполнения.
Однако добавление столбцов INCLUDEd увеличивает размер индекса, а также уровень обслуживания, необходимый для поддержания индекса в актуальном состоянии. Вы должны рассмотреть условие INCLUDE, но балансировать ее с другими требованиями вашей рабочей нагрузки.