Оптимизация запросов LINQ в C # .NET для MS SQL Server
Введение
LINQ был добавлен в .NET как новый мощный язык манипулирования данными. LINQ to SQL позволяет вам удобно общаться с СУБД, например, с помощью Entity Framework. Но часто при его использовании разработчики забывают рассмотреть, какой тип SQL-запроса будет сгенерирован запрашиваемым поставщиком (в нашем примере - Entity Framework). В этой статье мы рассмотрим, как именно вы можете оптимизировать производительность запросов LINQ.
Реализация
Давайте рассмотрим два наиболее важных момента на примере.
Во-первых, нам нужно создать тестовую базу данных в SQL Server. В этой базе данных мы создадим две таблицы, выполнив следующий запрос:
USE [TEST]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Ref](
[ID] [int] NOT NULL,
[ID2] [int] NOT NULL,
[Name] [nvarchar](255) NOT NULL,
[InsertUTCDate] [datetime] NOT NULL,
CONSTRAINT [PK_Ref] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, _
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Ref] ADD CONSTRAINT [DF_Ref_InsertUTCDate] _
DEFAULT (getutcdate()) FOR [InsertUTCDate]
GO
USE [TEST]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Customer](
[ID] [int] NOT NULL,
[Name] [nvarchar](255) NOT NULL,
[Ref_ID] [int] NOT NULL,
[InsertUTCDate] [datetime] NOT NULL,
[Ref_ID2] [int] NOT NULL,
CONSTRAINT [PK_Customer] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, _
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Customer] ADD CONSTRAINT [DF_Customer_Ref_ID] DEFAULT ((0)) FOR [Ref_ID]
GO
ALTER TABLE [dbo].[Customer] ADD CONSTRAINT [DF_Customer_InsertUTCDate] _
DEFAULT (getutcdate()) FOR [InsertUTCDate]
GO
Теперь давайте заполним таблицу Ref с помощью следующего скрипта. Если вы запустили скрипт и не сохранили его, SQL Complete от Devart может быть очень удобным. Он интегрируется с SSMS и Visual Studio и имеет функцию истории выполнения:
Рисунок 1 - Функция Execution History
Эта функция отображает историю запросов, которые были выполнены в SSMS:
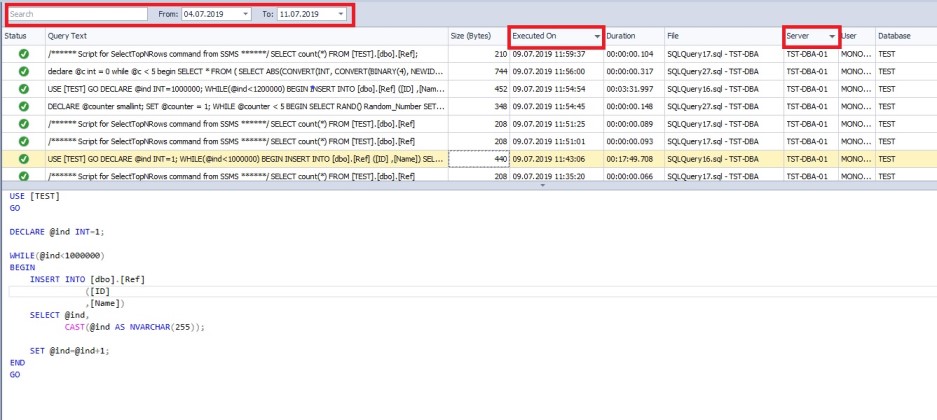
Рисунок 2 - История запросов
Обратите внимание, каким образом окно состоит из следующих элементов:
- Окно поиска для фильтрации результатов
- Поле диапазона дат для фильтрации результатов
- Результаты представлены в таблице. Вы можете сортировать данные по столбцам этой таблицы (используя клавишу SHIFT, вы можете выбрать набор столбцов для сортировки)
- Код выбранной строки
Таблица результатов содержит историю выполненных сценариев в SSMS и содержит следующие таблицы:
- Статус - показывает, был ли скрипт успешно выполнен
- Текст запроса - код скрипта
- Размер (в байтах) - размер скрипта в байтах
- Выполнено - дата и время выполнения сценария.
- Продолжительность - сколько времени потребовалось для выполнения скрипта
- Файл - имя файла или вкладки в SSMS, за которым следует имя экземпляра SQL Server, на котором был выполнен скрипт
- Сервер - имя экземпляра SQL Server, на котором был выполнен скрипт
- Пользователь - логин, под которым был выполнен скрипт
- База данных - контекст базы данных, в которой был выполнен скрипт
Мы можем найти необходимый запрос в этой таблице истории:
USE [TEST]
GO
DECLARE @ind INT=1;
WHILE(@ind<1200000)
BEGIN
INSERT INTO [dbo].[Ref]
([ID]
,[ID2]
,[Name])
SELECT
@ind
,@ind
,CAST(@ind AS NVARCHAR(255));
SET @ind=@ind+1;
END
GO
Аналогичным образом мы можем заполнить таблицу Customer с помощью следующего скрипта:
USE [TEST]
GO
DECLARE @ind INT=1;
DECLARE @ind_ref INT=1;
WHILE(@ind<=12000000)
BEGIN
IF(@ind%3=0) SET @ind_ref=1;
ELSE IF (@ind%5=0) SET @ind_ref=2;
ELSE IF (@ind%7=0) SET @ind_ref=3;
ELSE IF (@ind%11=0) SET @ind_ref=4;
ELSE IF (@ind%13=0) SET @ind_ref=5;
ELSE IF (@ind%17=0) SET @ind_ref=6;
ELSE IF (@ind%19=0) SET @ind_ref=7;
ELSE IF (@ind%23=0) SET @ind_ref=8;
ELSE IF (@ind%29=0) SET @ind_ref=9;
ELSE IF (@ind%31=0) SET @ind_ref=10;
ELSE IF (@ind%37=0) SET @ind_ref=11;
ELSE SET @ind_ref=@ind%1190000;
INSERT INTO [dbo].[Customer]
([ID]
,[Name]
,[Ref_ID]
,[Ref_ID2])
SELECT
@ind,
CAST(@ind AS NVARCHAR(255)),
@ind_ref,
@ind_ref;
SET @ind=@ind+1;
END
GO
Инструмент SQL Complete может помочь сохранить аккуратно отформатированный код ваших скриптов.
Таким образом, мы создали две таблицы - одна из них имеет более 1 миллиона строк, а другая - более 10 миллионов.
Теперь нам нужно создать тестовый проект в Visual Studio. Это будет консольное приложение Visual C # (.NET Framework).
Далее нам нужно добавить библиотеку для Entity Framework, чтобы мы могли взаимодействовать с базой данных.
Чтобы добавить эту библиотеку, щелкните правой кнопкой мыши проект и выберите ‘Manage NuGet Packages...’ в контекстном меню:
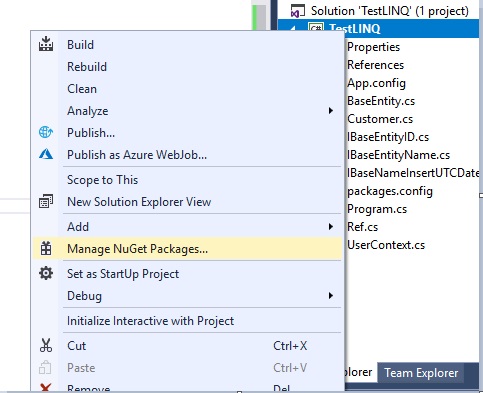
Рисунок 3 - Manage NuGet Packages...’ в контекстном меню
В открывшемся окне введите «Entity Framework» в поле поиска, выберите пакет Entity Framework и установите его:

Рисунок 4 - Установка пакета Entity Framework
Далее в файле App.config мы добавим следующий блок после элемента configSections:
<connectionstrings>
<add connectionstring="data source=MSSQL_INSTANCE_NAME;
Initial Catalog=TEST;Integrated Security=True;" name="DBConnection"
providername="System.Data.SqlClient">
</add>
</connectionstrings>
Убедитесь, что строка подключения введена в connectionString.
Теперь давайте создадим 3 интерфейса в отдельных файлах:
IBaseEntityID:namespace TestLINQ { public interface IBaseEntityID { int ID { get; set; } } }
IBaseEntityName:namespace TestLINQ { public interface IBaseEntityName { string Name { get; set; } } }
IBaseNameInsertUTCDate:namespace TestLINQ { public interface IBaseNameInsertUTCDate { DateTime InsertUTCDate { get; set; } } }
В отдельном файле создайте базовый класс BaseEntity для двух наших объектов, который будет содержать их общие поля:
namespace TestLINQ
{
public class BaseEntity : IBaseEntityID, IBaseEntityName, IBaseNameInsertUTCDate
{
public int ID { get; set; }
public string Name { get; set; }
public DateTime InsertUTCDate { get; set; }
}
}
Далее мы создадим два наших объекта, каждый в отдельном файле:
Ref:using System.ComponentModel.DataAnnotations.Schema; namespace TestLINQ { [Table("Ref")] public class Ref : BaseEntity { public int ID2 { get; set; } } }
Customer:using System.ComponentModel.DataAnnotations.Schema; namespace TestLINQ { [Table("Customer")] public class Customer: BaseEntity { public int Ref_ID { get; set; } public int Ref_ID2 { get; set; } } }
Наконец, давайте создадим контекст UserContext в отдельном файле:
using System.Data.Entity;
namespace TestLINQ
{
public class UserContext : DbContext
{
public UserContext()
: base("DbConnection")
{
Database.SetInitializer<usercontext>(null);
}
public DbSet<customer> Customer { get; set; }
public DbSet<ref> Ref { get; set; }
}
}
Таким образом, мы получаем решение для выполнения тестов оптимизации с помощью LINQ to SQL через Entity Framework для MS SQL Server:
Рисунок 5 - Решение для тестов оптимизации
Теперь давайте введем следующий код в файл Program.cs:
using System;
using System.Collections.Generic;
using System.Linq;
namespace TestLINQ
{
class Program
{
static void Main(string[] args)
{
using (UserContext db = new UserContext())
{
var dblog = new List<string>();
db.Database.Log = dblog.Add;
var query = from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID)
&& (e1.Ref_ID2 == e2.ID2)
select new { Data1 = e1.Name, Data2 = e2.Name };
var result = query.Take(1000).ToList();
Console.WriteLine(dblog[1]);
Console.ReadKey();
}
}
}
}
Когда мы запускаем проект, вот какой результат мы увидим в консоли:
SELECT TOP (1000)
[Extent1].[Ref_ID] AS [Ref_ID],
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent1]
INNER JOIN [dbo].[Ref] AS [Extent2] ON ([Extent1].[Ref_ID] = [Extent2].[ID]) _
AND ([Extent1].[Ref_ID2] = [Extent2].[ID2])
Как видите, запрос LINQ эффективно сгенерировал запрос SQL к СУБД MS SQL Server.
Теперь давайте изменим условие AND на OR в запросе LINQ:
var query = from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID)
|| (e1.Ref_ID2 == e2.ID2)
select new { Data1 = e1.Name, Data2 = e2.Name };
Запустите приложение еще раз.
Исключение будет брошено. Из описания ошибки мы увидим, что время ожидания операции истекло через 30 секунд:
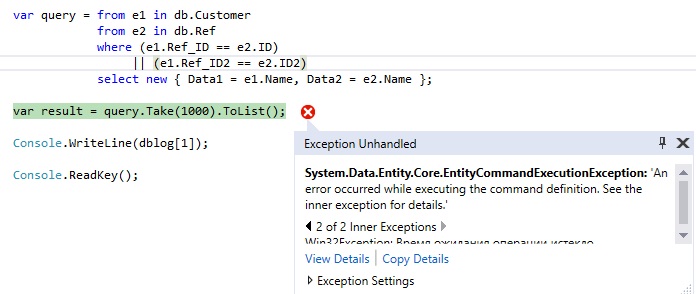
Рисунок 6 - Описание ошибки
Это запрос, который создал LINQ:
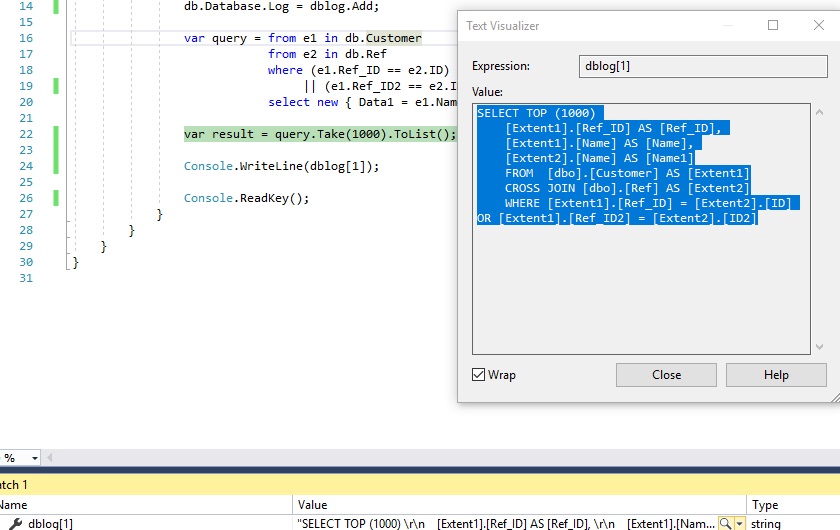
Рисунок 7 - запрос LINQ
Мы можем видеть, что выбор выполняется через декартово произведение двух наборов (таблиц):sets(tables):
SELECT TOP (1000)
[Extent1].[Ref_ID] AS [Ref_ID],
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent1]
CROSS JOIN [dbo].[Ref] AS [Extent2]
WHERE [Extent1].[Ref_ID] = [Extent2].[ID] OR [Extent1].[Ref_ID2] = [Extent2].[ID2]
Давайте перепишем запрос LINQ следующим образом:
var query = (from e1 in db.Customer
join e2 in db.Ref
on e1.Ref_ID equals e2.ID
select new { Data1 = e1.Name, Data2 = e2.Name }).Union_
(from e1 in db.Customer
join e2 in db.Ref
on e1.Ref_ID2 equals e2.ID2
select new { Data1 = e1.Name, Data2 = e2.Name });
В качестве результата мы получим следующий SQL-запрос:
SELECT
[Limit1].[C1] AS [C1],
[Limit1].[C2] AS [C2],
[Limit1].[C3] AS [C3]
FROM ( SELECT DISTINCT TOP (1000)
[UnionAll1].[C1] AS [C1],
[UnionAll1].[Name] AS [C2],
[UnionAll1].[Name1] AS [C3]
FROM (SELECT
1 AS [C1],
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent1]
INNER JOIN [dbo].[Ref] AS [Extent2] ON [Extent1].[Ref_ID] = [Extent2].[ID]
UNION ALL
SELECT
1 AS [C1],
[Extent3].[Name] AS [Name],
[Extent4].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent3]
INNER JOIN [dbo].[Ref] AS [Extent4] _
ON [Extent3].[Ref_ID2] = [Extent4].[ID2]) AS [UnionAll1]
) AS [Limit1]
К сожалению, в одном запросе LINQ может быть только одно условие подключения, поэтому мы можем добиться необходимых результатов, создав один запрос для каждого из двух условий, а затем объединяя их, используя Union для удаления повторяющихся строк.
Да, запросы в большинстве случаев будут неэквивалентными, учитывая, что могут быть возвращены дубликаты полной строки. Однако в реальной жизни дублирующиеся строки не нужны, и обычно это то, от чего вы хотите избавиться.
Теперь давайте сравним планы выполнения этих двух запросов:
- Среднее время выполнения CROSS JOIN составляет 195 с:
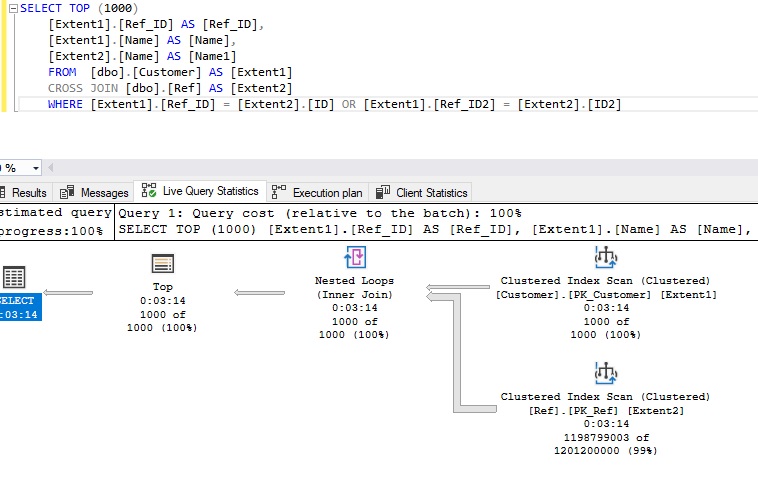
Рисунок 8 - Время выполнения для CROSS JOIN
Среднее время выполнения INNER JOIN-UNION составляет менее 24 секунд:
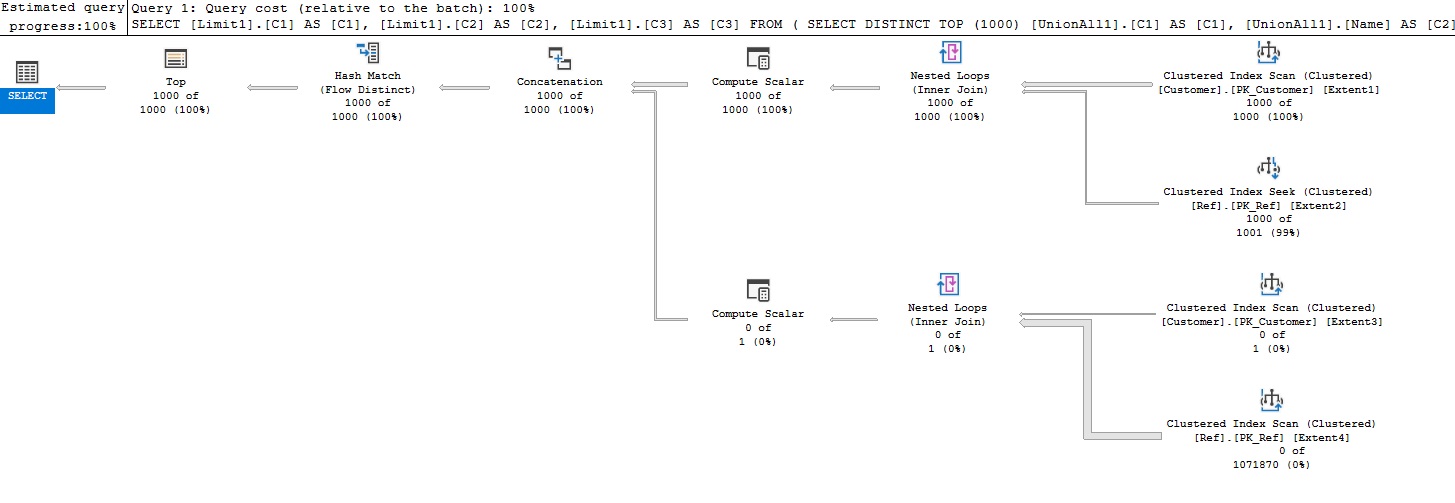
Рисунок 9 - Время выполнения INNER JOIN-UNION
Как видно из результатов, оптимизированный запрос LINQ работает в несколько раз быстрее, чем неоптимизированный запрос в этих двух таблицах с миллионами записей.
Для версии с условием AND запрос LINQ будет выглядеть следующим образом:
var query = from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID)
&& (e1.Ref_ID2 == e2.ID2)
select new { Data1 = e1.Name, Data2 = e2.Name };
Почти всегда в этом случае будет генерироваться правильный запрос SQL со временем выполнения приблизительно 24 секунды:
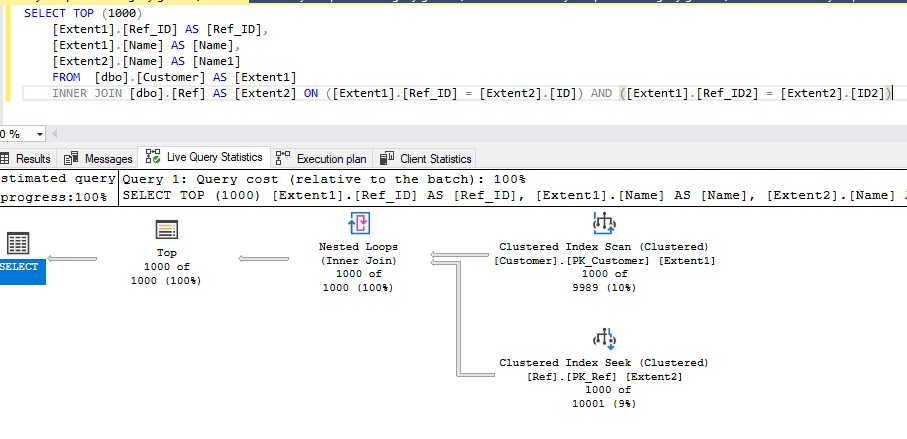
Рисунок 10 - Правильный SQL-запрос
Кроме того, для операций LINQ to Objects вместо запроса, который выглядит следующим образом:
var query = from e1 in seq1
from e2 in seq2
where (e1.Key1==e2.Key1)
&& (e1.Key2==e2.Key2)
select new { Data1 = e1.Data, Data2 = e2.Data };
мы можем использовать подобный запрос:
var query = from e1 in seq1
join e2 in seq2
on new { e1.Key1, e1.Key2 } equals new { e2.Key1, e2.Key2 }
select new { Data1 = e1.Data, Data2 = e2.Data };
где
Para[] seq1 = new[] { new Para { Key1 = 1, Key2 = 2, Data = "777" },
new Para { Key1 = 2, Key2 = 3, Data = "888" }, new Para { Key1 = 3, Key2 = 4, Data = "999" } };
Para[] seq2 = new[] { new Para { Key1 = 1, Key2 = 2, Data = "777" },
new Para { Key1 = 2, Key2 = 3, Data = "888" }, new Para { Key1 = 3, Key2 = 5, Data = "999" } };
Тип Para определяется следующим образом:
class Para
{
public int Key1, Key2;
public string Data;
}
Заключение
Мы рассмотрели некоторые аспекты оптимизации запросов LINQ для MS SQL Server. Кроме того, SQL Complete очень помог нам с поиском в истории запросов и с форматированием сценариев, которые мы использовали в этой статье.
К сожалению, даже опытные разработчики .NET часто забывают, что необходимо понимать, какие инструкции они используют в фоновом режиме. В противном случае они могут стать конфигураторами и установить переносную бомбу замедленного действия в будущем - как при масштабировании решения, так и при незначительном изменении внешних условий среды.
Исходные файлы для теста - сам проект, создание таблицы в базе данных TEST и заполнение этих таблиц данными можно найти здесь.
Кроме того, папка «Plans» из этого репозитория содержит планы выполнения запросов с условиями ИЛИ.
Помимо этого, есть отличное решение под названием dotConnect - это линейка компонентов доступа к данным от Devart для различных СУБД. Среди прочего, компоненты dotConnect поддерживают такие инструменты ORM, как Entity Framework Core и LinqConnect, которые позволяют работать с классами LINQ to SQL.