Избегание сворачивания: черная дыра производительности Power Query
Вы когда-нибудь задумывались о том, как осуществляются ваши преобразования Power Query: со стороны источника данных (на стороне сервера) или в локальной памяти (на стороне клиента)? Когда вы используете реляционный источник данных, запрос может быть запущен в источнике данных, но он зависит от преобразований. Некоторые преобразования могут быть переведены на язык запросов источника данных, а некоторые нет. В качестве примера; недавно Power BI Desktop добавила функцию, называемую Merge Columns.Она объединяет столбцы друг с другом, чтобы создать новый столбец или заменить их новым конкатенированным результатом. Раньше вы могли бы сделать конкатенацию с добавлением конкатенации просто с символом &, Вы добавляли новый настраиваемый столбец и записывали выражение M для конкатенации столбцов. Теперь, с новым Merge Column это намного проще: вы выбираете столбцы и применяете Merge Columns. Эта легкость приходит с ценой, высокой ценой, можно сказать, ценой снижения производительности Power Query и в результате Power BI! Merge Columns не поддерживает свертывание запросов, и это означает, что это плохо повлияет на производительность. В этом сообщении мы покажем вам, как это может вызвать проблему производительности и как ее можно решить. Обратите внимание, что здесь лишь пример слияния столбцов, эта ситуация может произойти и с некоторыми другими преобразованиями.
Query Folding
Трудно рассуждать об этой проблеме, не объясняя, что такое Query Folding, так что начнем с этого. Query Folding означает перевод преобразований Power Query (M) в собственный язык запросов источника данных (например, T-SQL). Другими словами; когда вы запускаете сценарий Power Query поверх базы данных SQL Server, Query Folding будет транслировать сценарий M в операторы T-SQL и получать окончательные результаты.
Вот пример M Script:
|
1 2 3 4 5 6 7 |
let Source = Sql.Databases("."), AdventureWorks2012 = Source{[Name="AdventureWorks2012"]}[Data], Sales_SalesOrderHeader = AdventureWorks2012{[Schema="Sales",Item="SalesOrderHeader"]}[Data], #"Added Conditional Column" = Table.AddColumn(Sales_SalesOrderHeader, "Custom", each if [SubTotal] >= 100 then "0" else "1" ) in #"Added Conditional Column" |
И вот сводная версия, переведенная на собственный T-SQL-запрос:
|
5 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
select [_].[SalesOrderID] as [SalesOrderID], [_].[RevisionNumber] as [RevisionNumber], [_].[OrderDate] as [OrderDate], [_].[DueDate] as [DueDate], [_].[ShipDate] as [ShipDate], [_].[Status] as [Status], [_].[OnlineOrderFlag] as [OnlineOrderFlag], [_].[SalesOrderNumber] as [SalesOrderNumber], [_].[PurchaseOrderNumber] as [PurchaseOrderNumber], [_].[AccountNumber] as [AccountNumber], [_].[CustomerID] as [CustomerID], [_].[SalesPersonID] as [SalesPersonID], [_].[TerritoryID] as [TerritoryID], [_].[BillToAddressID] as [BillToAddressID], [_].[ShipToAddressID] as [ShipToAddressID], [_].[ShipMethodID] as [ShipMethodID], [_].[CreditCardID] as [CreditCardID], [_].[CreditCardApprovalCode] as [CreditCardApprovalCode], [_].[CurrencyRateID] as [CurrencyRateID], [_].[SubTotal] as [SubTotal], [_].[TaxAmt] as [TaxAmt], [_].[Freight] as [Freight], [_].[TotalDue] as [TotalDue], [_].[Comment] as [Comment], [_].[rowguid] as [rowguid], [_].[ModifiedDate] as [ModifiedDate], case when [_].[SubTotal] >= 100 then '0' else '1' end as [Custom] from ( select [$Table].[SalesOrderID] as [SalesOrderID], [$Table].[RevisionNumber] as [RevisionNumber], [$Table].[OrderDate] as [OrderDate], [$Table].[DueDate] as [DueDate], [$Table].[ShipDate] as [ShipDate], [$Table].[Status] as [Status], [$Table].[OnlineOrderFlag] as [OnlineOrderFlag], [$Table].[SalesOrderNumber] as [SalesOrderNumber], [$Table].[PurchaseOrderNumber] as [PurchaseOrderNumber], [$Table].[AccountNumber] as [AccountNumber], [$Table].[CustomerID] as [CustomerID], [$Table].[SalesPersonID] as [SalesPersonID], [$Table].[TerritoryID] as [TerritoryID], [$Table].[BillToAddressID] as [BillToAddressID], [$Table].[ShipToAddressID] as [ShipToAddressID], [$Table].[ShipMethodID] as [ShipMethodID], [$Table].[CreditCardID] as [CreditCardID], [$Table].[CreditCardApprovalCode] as [CreditCardApprovalCode], [$Table].[CurrencyRateID] as [CurrencyRateID], [$Table].[SubTotal] as [SubTotal], [$Table].[TaxAmt] as [TaxAmt], [$Table].[Freight] as [Freight], [$Table].[TotalDue] as [TotalDue], [$Table].[Comment] as [Comment], convert(nvarchar(max), [$Table].[rowguid]) as [rowguid], [$Table].[ModifiedDate] as [ModifiedDate] from [Sales].[SalesOrderHeader] as [$Table] ) as [_] |
В качестве примера посмотрите, как сценарий условного столбца в M переводится в оператор Case в T-SQL.
Query Folding - хорошо или плохо?
Конечно, хорошо. Почему? потому что производительность намного выше для запуска преобразования на миллиарды записей в источнике данных, чем при переносе миллионов записей в кеш и применения к ним некоторых преобразований.
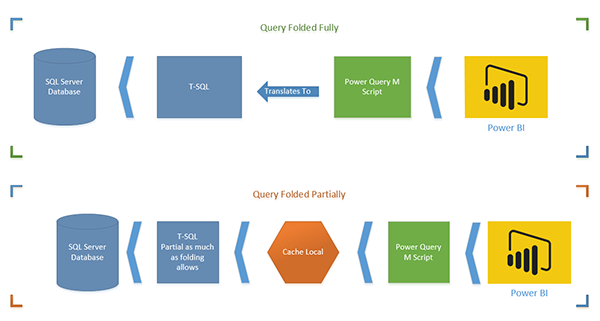
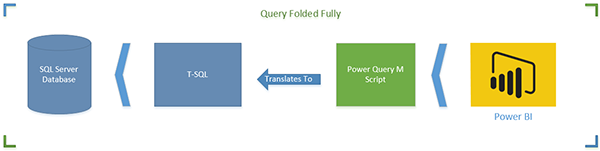
На первой диаграмме M-скрипт полностью свернут (переведен на T-SQL). Это лучшая ситуация. Операция на стороне сервера применяет все преобразования в наборе данных и возвращает только желаемый набор результатов.
На второй диаграмме частично поддерживается Query Folding (только до определенного шага). В этом случае T-SQL переносит данные до этого шага, а данные будут загружены в локальный кеш, а остальные преобразования происходят на стороне обработчика M. Вы должны максимально избегать этого варианта.
Могу ли я увидеть исходный запрос?
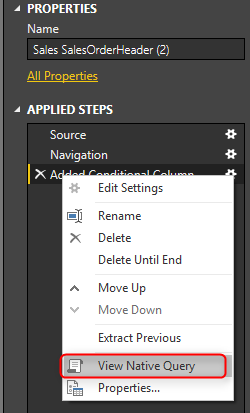
Вопрос, который может прийти в вашу голову прямо сейчас: могу ли я увидеть исходный запрос, который M-скрипт переводит на него? Ответ: Да. Если Query Folding поддерживается на шаге, вы можете щелкнуть правой кнопкой мыши по этому шагу и нажать «View Native Query».
Итак, почему не Query Folding?
По умолчанию функция Query Folding включена. Однако в некоторых случаях она не поддерживается. Например, если вы делаете некоторые преобразования в таблице SQL Server в Power Query, а затем присоединяете его к веб-запросу, Query Folding останавливается с момента, когда вы добавляете внешний источник данных. Это означает, что преобразования произойдут в данных таблицы SQL Server. Затем, прежде чем присоединяться к веб-запросу, он будет загружен в кеш, а затем, с помощью M-движка выполняются остальные шаги. Вам нужно будет переносить данные из разных источников данных в Power BI, и это способность, которую вам дает Power Query. Поэтому иногда вам нужно выйти за рамки Query Folding, и вряд ли есть лучший способ сделать это.
Есть также некоторые преобразования в Power Query, которые Query Folding не поддерживает. Пример? Merge Columns! К счастью, в этой ситуации есть обходные пути. Давайте углубимся в это более подробно.
Пример: Merge Columns
Merge Columns объединяет столбцы друг с другом в порядке выбора столбцов. Вы также можете указать символ(-ы) разделителя. Например, если вы хотите создать полное имя из имени и фамилии, вы можете выбрать их в правильном порядке, а на вкладке «Transform» или «Add Column» выберите « Merge Columns». Давайте посмотрим это на пример.
Предпосылка для запуска примера
Вам необходимо иметь базу данных AdvanetureWorksDW, установленную на SQL Server. Или же вы можете использовать любую таблицу в SQL Server, которая имеет два столбца строки, которые могут быть объединены.
Преобразование Merge Columns
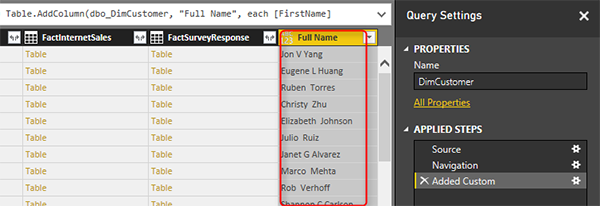
Создайте новый файл Power BI в Power BI Desktop и получите данные с SQL Server с режимом импорта данных. Получите данные только из таблицы DimCustomer и выберите Edit. Когда будете в Query Editor, выберите «Имя», «Второе имя» и «Фамилия» (First Name, Middle Name, Last Name) в правильном порядке, а затем в «Add Column» выберите «Merge Columns».
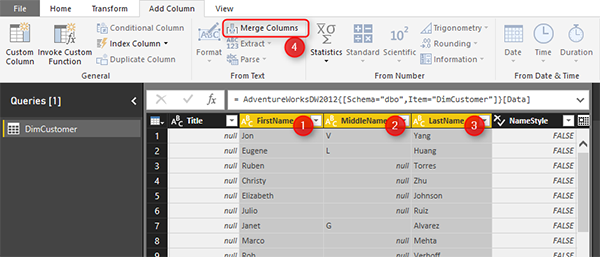
В Merge Columns укажите пробел в качестве разделителя и назовите новый столбец Full Name.
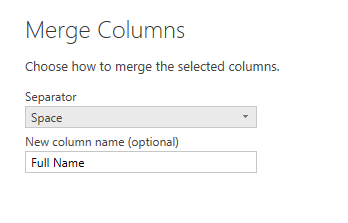
Вы увидите, что новый столбец генерирует просто и добавляет к концу всех столбцов. Вы также можете заметить, что в Merge Columns используется функция Text.Combine Power Query для объединения столбцов друг с другом.
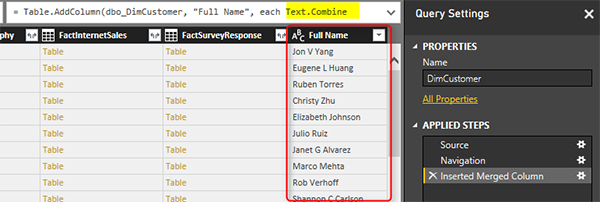
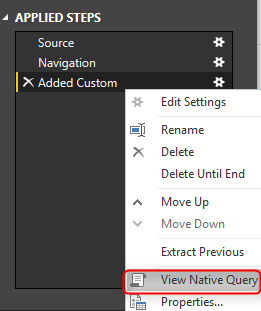
Теперь, чтобы увидеть проблему с Query Folding, щелкните правой кнопкой мыши на шаге Inserted Merge Column в разделе Applied Steps. Вы увидите, что View Native Query отключен.
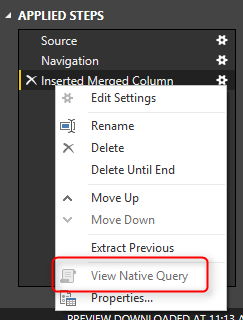
Общее правило заключается в следующем: когда View Native Query не включен, этот шаг не будет свернут! это означает, что данные будут загружены в кеш-память за шагом до этого шага, а затем остальная часть операции будет происходить локально. Чтобы понять, как это работает, щелкните правой кнопкой мыши на шаге, перед которым была Навигация. Вы увидите View Native Query. Нажмите на него, и вы можете увидеть запрос T-SQL для следующего:
Transact-SQL
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
select [$Table].[CustomerKey] as [CustomerKey], [$Table].[GeographyKey] as [GeographyKey], [$Table].[CustomerAlternateKey] as [CustomerAlternateKey], [$Table].[Title] as [Title], [$Table].[FirstName] as [FirstName], [$Table].[MiddleName] as [MiddleName], [$Table].[LastName] as [LastName], [$Table].[NameStyle] as [NameStyle], [$Table].[BirthDate] as [BirthDate], [$Table].[MaritalStatus] as [MaritalStatus], [$Table].[Suffix] as [Suffix], [$Table].[Gender] as [Gender], [$Table].[EmailAddress] as [EmailAddress], [$Table].[YearlyIncome] as [YearlyIncome], [$Table].[TotalChildren] as [TotalChildren], [$Table].[NumberChildrenAtHome] as [NumberChildrenAtHome], [$Table].[EnglishEducation] as [EnglishEducation], [$Table].[SpanishEducation] as [SpanishEducation], [$Table].[FrenchEducation] as [FrenchEducation], [$Table].[EnglishOccupation] as [EnglishOccupation], [$Table].[SpanishOccupation] as [SpanishOccupation], [$Table].[FrenchOccupation] as [FrenchOccupation], [$Table].[HouseOwnerFlag] as [HouseOwnerFlag], [$Table].[NumberCarsOwned] as [NumberCarsOwned], [$Table].[AddressLine1] as [AddressLine1], [$Table].[AddressLine2] as [AddressLine2], [$Table].[Phone] as [Phone], [$Table].[DateFirstPurchase] as [DateFirstPurchase], [$Table].[CommuteDistance] as [CommuteDistance], [$Table].[FullName] as [FullName] from [dbo].[DimCustomer] as [$Table] |
Вы можете видеть, что это простой запрос из таблицы DimCustomer. Что произойдет в этом сценарии, так это то, что Power Query не сможет перевести Text.Combine в T-SQL Query. Таким образом, данные до предыдущего шага будут загружены в кеш. Это означает, что запрос для предыдущего шага (который выше запроса) будет запущен на сервере базы данных, результат поступит в кэш, а затем в локальном кеше будет выполняться Text.Combine. Вот схема того, как она работает;
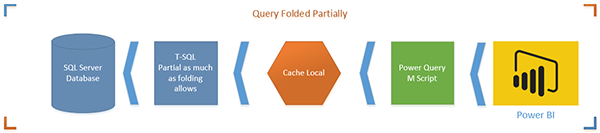
В этом примере набор данных настолько мал, но если набор данных будет большим, то не произойдет сворачивания, что вызовет проблемы с производительностью. Гораздо больше времени занимает загрузка всего набора данных в кэш и дальнейшее применение трансформаций, чем если осуществить трансформации в источнике данных и затем загрузить результат в Power BI.
Решение: Простой конкатенат с добавлением столбца
Теперь удалите шаг для Inserted Merged Column и перейдите на вкладку Add Column и выберите Custom Column
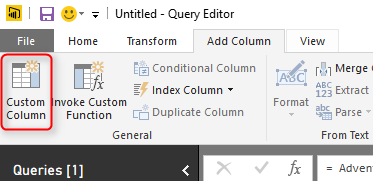
В Add Custom Column напишите ниже выражение для создания полного имени;
|
1 2 3 4 5 6 7 8 9 |
= [FirstName] & " " & (if [MiddleName]=null then "" else [MiddleName]) & " " &[LastName] |
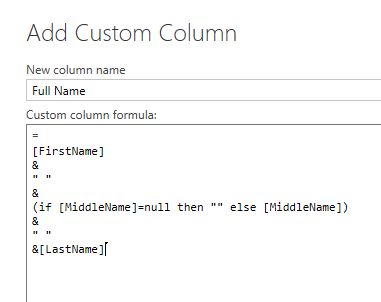
Это выражение использовало символ конкатенации, который является &, а также проверило, является ли Middle Name равным null или нет. Результат в Power Query одинаковый, и он генерирует столбец Full Name, как в предыдущем примере.
Однако для Query Folding это отличается. Щелкните правой кнопкой мыши на добавленном шаге Custom, и на этот раз вы увидите Native Query.
Запрос просто совпадает с новым добавленным конкатенированным столбцом.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
select [_].[CustomerKey] as [CustomerKey], [_].[GeographyKey] as [GeographyKey], [_].[CustomerAlternateKey] as [CustomerAlternateKey], [_].[Title] as [Title], [_].[FirstName] as [FirstName], [_].[MiddleName] as [MiddleName], [_].[LastName] as [LastName], [_].[NameStyle] as [NameStyle], [_].[BirthDate] as [BirthDate], [_].[MaritalStatus] as [MaritalStatus], [_].[Suffix] as [Suffix], [_].[Gender] as [Gender], [_].[EmailAddress] as [EmailAddress], [_].[YearlyIncome] as [YearlyIncome], [_].[TotalChildren] as [TotalChildren], [_].[NumberChildrenAtHome] as [NumberChildrenAtHome], [_].[EnglishEducation] as [EnglishEducation], [_].[SpanishEducation] as [SpanishEducation], [_].[FrenchEducation] as [FrenchEducation], [_].[EnglishOccupation] as [EnglishOccupation], [_].[SpanishOccupation] as [SpanishOccupation], [_].[FrenchOccupation] as [FrenchOccupation], [_].[HouseOwnerFlag] as [HouseOwnerFlag], [_].[NumberCarsOwned] as [NumberCarsOwned], [_].[AddressLine1] as [AddressLine1], [_].[AddressLine2] as [AddressLine2], [_].[Phone] as [Phone], [_].[DateFirstPurchase] as [DateFirstPurchase], [_].[CommuteDistance] as [CommuteDistance], [_].[FullName] as [FullName], ((([_].[FirstName] + ' ') + (case when [_].[MiddleName] is null then '' else [_].[MiddleName] end)) + ' ') + [_].[LastName] as [Full Name] from [dbo].[DimCustomer] as [_] |
На этот раз промежуточного кеша не будет. Трансформация происходит в источнике данных с запросом T-SQL, и результат будет загружен в Power BI.
Как узнать, какая трансформация сворачивается?
Отличный вопрос. Важно понять, какие шаги или преобразования сворачиваются, а какие нет. Чтобы понять, что просто щелкните правой кнопкой мыши на каждом шаге и посмотрите, включен ли просмотр Native Query или нет. Если он включен, для этого шага поддерживается функция Query Folding, в обратном случае - нет. Также обратите внимание, что функция Query Folding не поддерживается для источников данных, таких как веб-запрос или CSV, или что-то в этом роде. Query Folding на данный момент поддерживается только для хранилищ данных, поддерживающих собственный язык запросов. Для Web, Folder, CSV ... нет родного языка запросов, поэтому вам не нужно беспокоиться о Query Folding.
* Важное примечание. На момент написания этого сообщения Merge Columns не поддерживает Query Folding. Команда Power Query Team работает над тем, чтобы решить эту проблему. Слияние столбцов, скорее всего, будет поддерживать свертывание запросов очень скоро в результате исправления ошибок. Однако всегда есть некоторые другие преобразования, которые не поддерживают свертывание запроса. Этот пост написан, чтобы дать вам понять, какая проблема может произойти, и как ее разрешить.
Мой совет вам в качестве наилучшей практики производительности заключается в том, что при работе с реляционным источником данных (например, SQL Server) всегда проверяйте Query Folding. Иногда он не поддерживается, поэтому используйте другой подход для преобразования. Не попадайте в черную дыру, не используя сворачивание, иначе ваш запрос может занять годы для запуска.