Что такое взаимоблокировка SQL Server?

Если вы получили вышеуказанную ошибку 1025, это означает, что ваш процесс столкнулся со взаимоблокировкой, был выбран в качестве жертвы взаимоблокировки и завершен. Взаимная блокировка возникает, когда две или более транзакций удерживают взаимно несовместимые блокировки, и не может продолжаться без вмешательства SQL Server.
Вообще говоря, наиболее распространенные взаимоблокировки возникают, когда два (или более) сеанса, которые удерживают монопольную блокировку, не могут установить другую блокировку, поскольку ресурс уже заблокирован другой конкурирующей транзакцией.
Давайте предположим, что следующие два сеанса выполнялись одновременно:
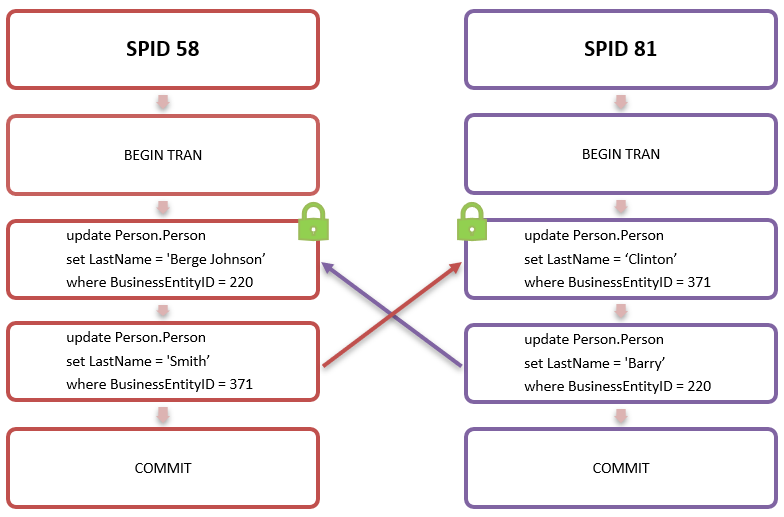
SPID 58 обновил столбец «LastName» в таблице «Person.Person» для строки с «BusinessEntityID» (ID) 220, и одновременно SPID 81 выполнил один и тот же оператор обновления для строки с ID 371. Два сеанса удерживали монопольную блокировку на строки с ID 220 и 371 соответственно, но они еще не зафиксированы. SPID 58 затем попытался обновить строку с идентификатором 371, который был заблокирован с помощью SPID 81, а SPID 81 попытался обновить строку с идентификатором 220, который, в свою очередь, был заблокирован с помощью SPID 58: ни один сеанс не мог быть продолжен.
Давайте посмотрим на график взаимоблокировок:
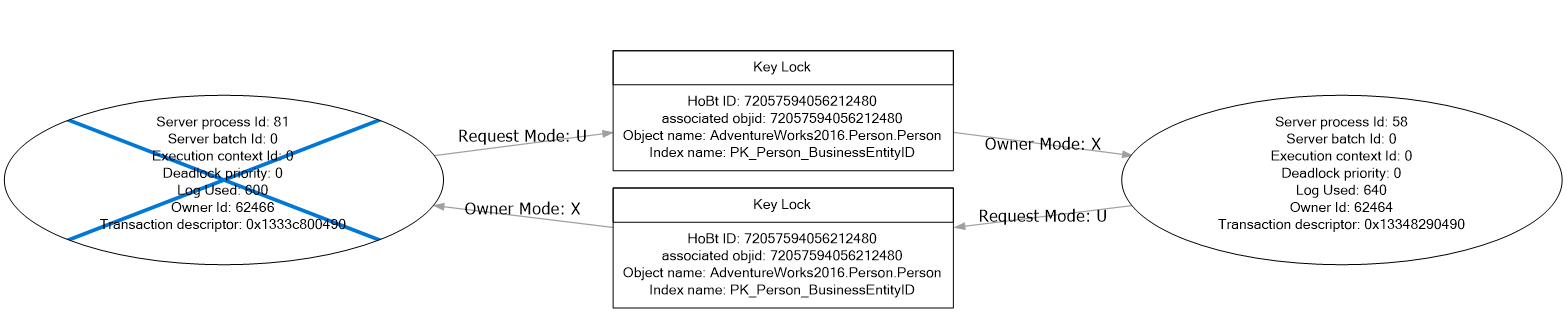
Как видно из приведенного выше графика, оба SPID 81 и 58 имели эксклюзивную блокировку ключа, затем они запросили блокировку обновления для строки, которая уже была заблокирована другим SPID. На этом этапе ни одна из сессий не может быть продолжена, и SQL Server решил убить SPID 81, откатив работу до сих пор. SPID 56 успешно завершен.
Механизм базы данных проверяет ситуацию такого типа приблизительно каждые 5 секунд (в зависимости от частоты взаимоблокировок), используя системный процесс под названием «LOCK_MONITOR», и завершает (убивает) транзакцию, известную как жертва взаимоблокировки, которая выполнила наименьшее количество работы или наименее дорогой для отката. Это устраняет тупик и позволяет другим транзакциям продолжить и возобновить свою работу.
Единственное исключение из вышеприведенного оператора - если приоритет взаимоблокировки был изменен на уровне сеанса. По умолчанию приоритет взаимоблокировки установлен на 0, что означает, что ядро базы данных решает, какая транзакция должна быть прервана. Если для приоритета взаимоблокировки установлено другое значение, SQL Server завершает транзакцию с наименьшим приоритетом взаимоблокировки
|
Deadlock Priority (Приоритет блокировки) |
Значенue |
|
LOW |
-5 |
|
NORMAL (default) |
0 |
|
HIGH |
5 |
|
NUMERIC VALUE (range) |
-10 to 10 |
|
--Check your session's deadlock priority SELECT deadlock_priority FROM SYS.dm_exec_sessions WHERE session_id = @@SPID
--Change deadlock priority to HIGH SET DEADLOCK_PRIORITY HIGH GO
--Change deadlock priority to a numeric value SET DEADLOCK_PRIORITY -10 GO |
Это очень простой пример, чтобы понять концепцию правильно, но существуют и другие типы взаимоблокировок, и они иногда становятся очень сложными с участием нескольких сеансов. Другими распространенными типами взаимоблокировок являются взаимоблокировки преобразования и поиска ключей.
Как следует из названия, взаимоблокировки преобразования возникают, когда транзакция пытается преобразовать полученную блокировку в другую монопольную блокировку или пытается получить две блокировки по отдельности и одновременно, но это невозможно, поскольку ресурс уже заблокирован другой транзакцией. Этот тип взаимоблокировок может встречаться при использовании намеренных блокировок: Shared with Intent Exclusive (SIX), Shared Intent Update (SIU) and Update Intent Exclusive (UIX).
Блокировки поиска ключей очень интересны, потому что они могут возникать между двумя сессиями, которые выполняют один оператор. Недавно мы столкнулись с этим типом взаимоблокировок для клиента, который испытал сотни! Из нескольких сеансов был задействован только один оператор обновления, и план выполнения выглядел так, как показано ниже:
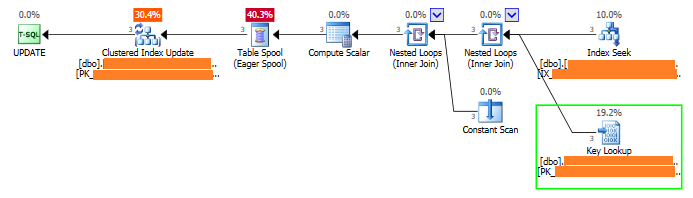
Как вы можете видеть, SQL Server выполнил поиск по некластеризованному индексу, который не был покрыт, и затем просмотр по кластерному индексу, чтобы получить не включенные столбцы. Из-за поиска каждый сеанс должен был получить две эксклюзивные блокировки: одну для обновления строк в кластеризованном индексе, а другую для выполнения поиска ключа. Эта ситуация может привести к взаимоблокировке, и в этом случае клиент испытал сотни из них из-за высокого параллелизма.
Взаимоблокировки - не зло
Взаимные блокировки не следует путать с блокировкой, когда сеанс (A) запрашивает блокировку для ресурса, который уже заблокирован другим сеансом (B). В этом случае сеанс A будет ждать, пока сеанс B завершится, и снимет блокировку. Блокировка может быть критической проблемой, и встречались системы с цепочками блокировки, включающими десятки сеансов в течение нескольких часов.
Некоторые люди склонны паниковать, когда видят взаимоблокировки. Случалось, что клиенты поднимали проблемы с P1, но после расследования было обнаружено, что через несколько часов у них было несколько взаимоблокировок для хранимой процедуры, которая вызывалась тысячи раз в минуту.
Как объяснялось ранее в этом блоге, SQL Server внутренне обрабатывает и устраняет взаимоблокировки, которые в противном случае привели бы к бесконечной блокировке между двумя или более сеансами.
Если ваша база данных имеет высокую скорость транзакций с тысячами одновременных пакетов / транзакций в секунду, спорадические взаимоблокировки на самом деле не плохи и предотвращают такие проблемы, как цепочки блокировки, длительные запросы и тайм-ауты. Это, конечно, при условии, что ваше приложение обрабатывает ошибки с помощью надежной логики повторов!
Вы бы предпочли, чтобы два или более сеанса ждали друг друга всегда или у вас бывали отдельные спорадические ошибки, которые можно быстро обработать и повторить на уровне приложений? Скорее последнее, но вы несете ответственность за принятие правильного решения в зависимости от ваших потребностей. С другой стороны, если вы начинаете видеть десятки или сотни взаимоблокировок, то что-то не так.
Как обнаружить блокировки
Есть несколько способов выявления и обнаружения взаимоблокировок, включая сторонние инструменты, такие как SentryOne. SQL Server предоставляет несколько различных способов обнаружения и сбора информации о взаимоблокировках. Вот некоторые из них:
1. Флаги трассировки
Включите флаги трассировки 1204 и / или 1222 для печати информации о взаимоблокировках в журнале ошибок SQL Server:
|
--#Enable Trace Flags Globally DBCC TRACEON(1204,1222,-1) GO --#Check Trace Flags Status DBCC TRACESTATUS(1204,1222,-1) GO --#Disable Trace Flags Globally DBCC TRACEOFF(1204,1222,-1) GO |
Вышеприведенные команды включают флаги трассировки глобально до следующего перезапуска - просто помните, что вы добавляете флаги в качестве параметров запуска в диспетчере конфигурации SQL Server, если хотите, чтобы изменение было постоянным в случае перезапуска SQL Server:
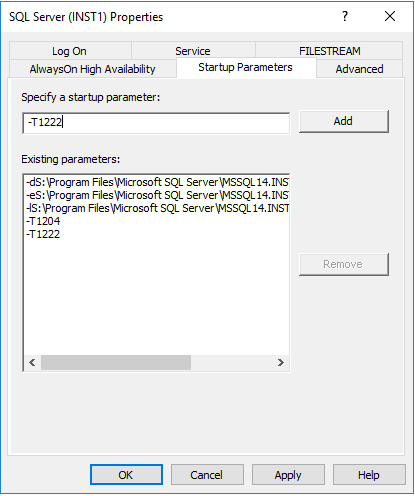
Лично мы не рекомендовали бы использовать этот метод, поскольку он может легко сделать ваш журнал ошибок SQL Server очень кривым и чрезвычайно трудным для чтения, когда речь идет о расследовании других проблем. Включив оба флага трассировки, мы подсчитали 57 строк в журнале ошибок SQL Server для этой простой взаимоблокировки. Представьте, насколько большим и трудным станет чтение вашего журнала ошибок, если у вас есть десятки или сотни взаимоблокировок. Далеко от идеала.
2. SQL Server Profiler
Вы можете запустить трассировку профилировщика для захвата событий взаимоблокировок. SQL Server Profiler устарел и может быть удален в будущей версии SQL Server, однако он все еще доступен в SQL Server 2019. Это очень надежный инструмент для устранения проблем с производительностью SQL Server, и мы все еще используем его, если нужно запустить быструю трассировку в системе. Это также очень просто в использовании.
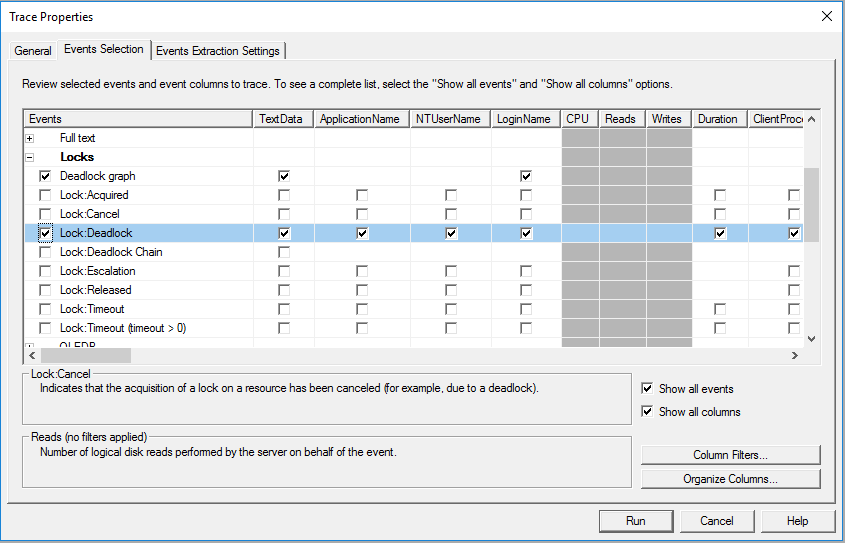
На вкладке выбора событий новой трассировки SQL Server Profiler выберите события Deadlock:Graph’ и ‘Lock:Deadlock’ в категории ‘Locks’:
3. Extended Events
Расширенные события (XE) - безусловно, самый распространенный и эффективный метод захвата взаимоблокировок.
Расширенное событие ‘system health’, которое создается и включается по умолчанию, содержит некоторые общие события работоспособности SQL Server, а также фиксирует взаимоблокировки. Однако взаимная блокировка не обязательно может быть захвачена ‘system health’ XE, поскольку расширенные события допускают потерю одного события по умолчанию и в соответствии с рекомендациями.
Это означает, что расширенное событие может игнорировать и пропускать отдельные события. Графики взаимоблокировок могут быть довольно большими (даже несколько МБ), и если SQL Server необходимо выбрать между отслеживанием нескольких событий или одним графом взаимоблокировок 3 МБ, он может игнорировать взаимоблокировку и выбрать протоколирование других событий.
Если у вас есть серьезная проблема взаимоблокировки, которая затрагивает вашу систему, и вам нужно перехватывать каждое отдельное вхождение без исключений, вы должны создать выделенное расширенное событие для взаимоблокировок и запретить потерю события, хотя это НЕ рекомендуется в обычных обстоятельствах.
Создайте новый XE для взаимоблокировок без потери событий.
|
IF EXISTS(SELECT * FROM sys.server_event_sessions WHERE name='Deadlock_XE') DROP EVENT session Deadlock_XE ON SERVER; GO CREATE EVENT SESSION [Deadlock_XE] ON SERVER ADD EVENT sqlserver.xml_deadlock_report ADD TARGET package0.event_file (SET filename=N'Deadlock_XE',max_rollover_files=(10)), ADD TARGET package0.ring_buffer WITH (STARTUP_STATE=ON,EVENT_RETENTION_MODE=NO_EVENT_LOSS,MAX_MEMORY=4MB,MAX_EVENT_SIZE=4MB) GO
ALTER EVENT SESSION [Deadlock_XE] ON SERVER STATE = START GO
--Cleanup DROP EVENT SESSION [Deadlock_XE] ON SERVER GO |
Запрос взаимоблокировки XE
|
--1. Find Deadlocks Extended Events and get the path of the target file (File Path) SELECT CAST(target_data as xml) FROM sys.dm_xe_session_targets xet INNER JOIN sys.dm_xe_sessions xes ON xes.address = xet.event_session_address INNER JOIN sys.dm_xe_session_events xee ON xes.address = xee.event_session_address WHERE xee.event_name = 'xml_deadlock_report' AND xet.target_name = 'event_file';
--2. Query Extended Events Deadlocks Reports DECLARE @StartTime datetime = '2019-04-16 00:00:00.003', @EndTime datetime = '2019-04-16 23:59:59.997' select @StartTime, @EndTime
;with deadlocks as ( SELECT CAST(DATEADD(mi,DATEDIFF(mi, GETUTCDATE(), CURRENT_TIMESTAMP),xevents.event_data.value('(event/@timestamp)[1]','datetime2')) AS datetime) AS [Event Time] ,CAST(xet.event_data as xml) AS [Deadlock Report] from sys.fn_xe_file_target_read_file ('[target files path]\*.xel' --Replace with file path you get from query 1 ,'[target files path]\*.xem', null, null) xet --Replace with file path you get from query 1 cross apply (select cast(event_data as XML) as event_data) as Xevents where object_name = 'xml_deadlock_report' ) SELECT [Event Time] ,[Deadlock Report] FROM deadlocks WHERE [Event Time]>= @StartTime and [Event Time] < @EndTime;
--3. Query Extended Events Deadlocks details DECLARE @StartTime datetime = '2019-04-16 00:00:00.003', @EndTime datetime = '2019-04-16 23:59:59.997'
select cast(getdate() as datetime2) CREATE TABLE #Deadlocks
DeadlockID int identity(1,1), Event_Data XML, EventTime datetime
;with deadlocks as ( SELECT CAST(DATEADD(mi,DATEDIFF(mi, GETUTCDATE(), CURRENT_TIMESTAMP),xevents.event_data.value('(event/@timestamp)[1]','datetime2')) AS datetime) AS [Event Time] ,CAST(xet.event_data as xml) AS [Deadlock Report] from sys.fn_xe_file_target_read_file ('[target files path]\*.xel' --Replace with file path you get from query 1 ,'[target files path]\*.xem', null, null) xet --Replace with file path you get from query 1 cross apply (select cast(event_data as XML) as event_data) as Xevents where object_name = 'xml_deadlock_report' ) INSERT INTO #Deadlocks SELECT [Deadlock Report] ,[Event Time] FROM deadlocks WHERE [Event Time]>= @StartTime and [Event Time] < @EndTime
;WITH Deadlocks_CTE AS ( select DeadlockID ,event_data ,EventTime --,event_data.value('(//process-list/process/@id)[1]','varchar(200)') --,event_data.value('(//process-list/process/@waitresource)[1]','varchar(200)') ,Deadlock.Process.value('@waitresource', 'varchar(100)') AS WaitType ,Deadlock.Process.value('@waittime', 'int') AS WaitTime ,Deadlock.Process.value('@spid', 'int') AS SPID ,Deadlock.Process.value('@ownerId','int') AS OwnerID ,Deadlock.Process.value('@lockMode','varchar(10)') AS LockMode ,Deadlock.Process.value('@priority','int') AS DeadlockPriority ,Deadlock.Process.value('@trancount','int') AS TranCount ,Deadlock.Process.value('@lastbatchstarted','datetime') AS LastBatchStarted ,Deadlock.Process.value('@lastbatchcompleted','datetime') AS LastBatchCompleted ,Deadlock.Process.value('@clientapp','varchar(200)') AS Application ,Deadlock.Process.value('@hostname','varchar(100)') AS HostName ,Deadlock.Process.value('@isolationlevel','varchar(100)') AS IsolationLevel ,Deadlock.Process.value('@xactid','int') AS TranID ,Deadlock.Process.value('@currentdbname','varchar(100)') AS DBName ,Deadlock.Process.value('@loginname','varchar(100)') AS LoginName ,Deadlock.Process.value('@id','varchar(100)') AS ProcessID ,input.Buffer.query('.') as InputBuffer ,victim.list.value('@id','varchar(100)') AS VictimID from #Deadlocks cross apply #Deadlocks.event_data.nodes('//process-list/process') AS Deadlock(Process) cross apply #Deadlocks.event_data.nodes('//deadlock/victim-list/victimProcess') AS Victim(List) CROSS APPLY Deadlock.Process.nodes('executionStack') AS Execution(Frame) CROSS APPLY Deadlock.Process.nodes('inputbuf') AS Input(Buffer) CROSS APPLY (SELECT Deadlock.Process.value('@id', 'varchar(50)') ) AS Process (ID) ) SELECT DeadlockID ,EventTime as [Event Time] ,ProcessID ,CASE WHEN ProcessID = VictimID THEN 1 ELSE 0 END AS [Is Victim] ,SPID ,CASE Application WHEN '' THEN 'N/A' ELSE Application END AS [App Name] ,CASE HostName WHEN '' THEN 'N/A' ELSE HostName END AS [Host Name] ,LoginName ,DBName as [Database Name] --,table ,WaitType as [Wait Type] ,LockMode ,WaitTime as [Wait Time(ms)] ,TranCount ,IsolationLevel ,DeadlockPriority ,InputBuffer as [SQL Command] ,event_data as [Deadlock Graph] FROM Deadlocks_CTE
--Cleanup --DROP TABLE #Deadlocks |
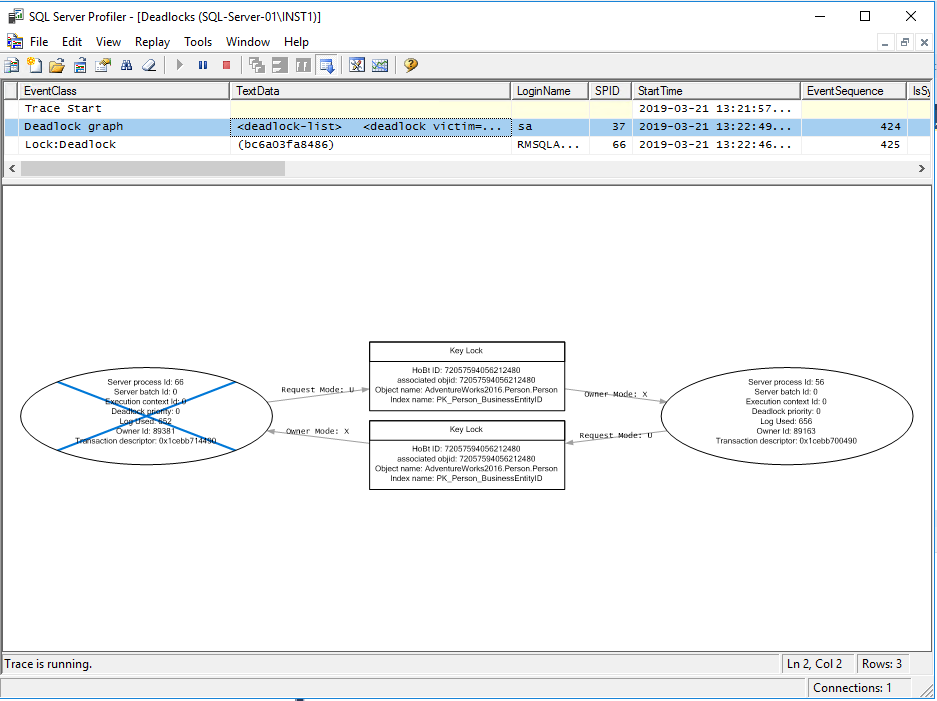
Чтобы просмотреть расширенные события взаимоблокировок в SSMS, выберите Management, Extended Events, Sessions, разверните расширенный сеанс событий взаимоблокировки и щелкните правой кнопкой мыши файл событий, чтобы просмотреть целевые данные. Это будет выглядеть как на скриншоте ниже:
Как устранить взаимоблокировки
Уменьшить вероятность может быть очень сложно, если не невозможно в тех же случаях. Тем не менее, есть несколько способов смягчить их и уменьшить количество случаев:
- Убедитесь, что вы пишете запросы согласованным образом, а строки таблиц изменяются в том же порядке.
- Избегайте дублирования - т.е. избегайте одновременной загрузки больших объемов данных, процессов ETL и/или обслуживания индекса, если это возможно.
- Исследуйте связанные запросы и проверьте блокировки/эскалации блокировок. Вы можете обнаружить, что ваш запрос привел к эскалации блокировки (то есть от хорошей блокировки строки/ключа к странице, экстенту или даже к блокировке таблицы) и блокирует больше данных, чем на самом деле нужно.
- Создавайте вспомогательные индексы, чтобы сделать ваш запрос максимально эффективным и предотвратить большие сканирования, ненужные блокировки, поиски и эскалацию блокировок.
- Запускайте большие операторы DML в пакетном режиме, чтобы предотвратить масштабное сканирование и блокировку эскалаций.
- Установите приоритет взаимоблокировки - если вы знаете, что процесс более критичен, чем другие, и ДОЛЖЕН завершиться, вы можете установить для приоритета взаимоблокировки значение HIGH или значение a больше 0 (по умолчанию).
Резюме
Взаимные блокировки возникают, когда два (или более) сеанса не могут быть продолжены, поскольку они содержат взаимно несовместимые блокировки для одних и тех же ресурсов. SQL Server внутренне обрабатывает взаимоблокировки и устраняет их, убивая транзакцию с наименьшим приоритетом взаимоблокировки или ту, которая выполнила наименьший объем работы. Пишите запросы разумно и используйте правильные индексы, чтобы минимизировать ненужные блокировки.
Мы решили проблему поиска взаимоблокировки, упомянутую выше в этом блоге, создав закрывающий некластеризованный индекс, что исключило необходимость поиска ключа и дополнительной исключительной блокировки.