Что нового в SQL Server 2019 CTP 2.1: более быстрые функции
Некоторое время назад мы говорили с вами о том, как Microsoft работает над созданием более быстрых пользовательских функций. Теперь, когда следующий предварительный просмотр (CTP2.1) SQL Server 2019 отсутствует, вы можете начать получать информацию о функции Froid, повышающей производительность. Вот документация по нему - посмотрим, как это работает.
Используя базу данных StackOverflow2010, скажем, наша компания имеет скалярную пользовательскую функцию, которую мы используем для расчета количества значков, которые пользователь заработал:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE OR ALTER FUNCTION dbo.ScalarFunction ( @uid INT ) RETURNS BIGINT WITH RETURNS NULL ON NULL INPUT, SCHEMABINDING AS BEGIN DECLARE @BCount BIGINT; SELECT @BCount = COUNT_BIG(*) FROM dbo.Badges AS b WHERE b.UserId = @uid GROUP BY b.UserId; RETURN @BCount; END; GO |
Раньше производительность для этого действительно отставала. Если я возьму 1000 пользователей и вызову функцию, чтобы получить их значения счетчика:
|
1 2 3 4 5 |
SELECT TOP 1000 u.DisplayName, dbo.ScalarFunction(u.Id) FROM dbo.Users AS u GO |
План выполнения выглядит просто:
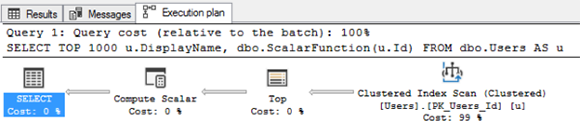
План 2017, который скрывает работу скаляра
Но это действительно ужасно:
- Он не показывает все, что делает скалярная функция
- Это дико недооценивает работу (скаляры фиксируют крошечные затраты независимо от работы, которую они выполняют)
- Он не показывает логические чтения, выполняемые функцией
- И, конечно, он вызывает эту функцию 1000 раз - один раз для каждого возвращаемого нами пользователя
Метрики:
- Время воспроизведения: 17 секунд
- Время процессора: 56 секунд
- Логические чтения: 6 643 089
Теперь давайте попробуем в SQL Server 2019.
Моя база данных должна быть в режиме совместимости 2019, чтобы включить Froid, функцию-вложение магии. Повторите тот же запрос, и показатели сильно отличаются:
- Время выполнения: 4 секунды
- Время процессора: 4 секунды
- Логические чтения: 3,247,991 (что по-прежнему звучит плохо, но потерпите)
План выполнения выглядит хуже:
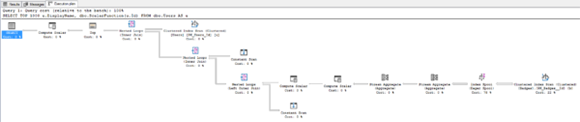
План 2019, показывающий жуткость встроенной функции
Вероятно, ваша первая мысль: «Мать честная, этот план показывает больше работы», но дело в том, что теперь он показывает работу, связанную с этой функцией. Раньше вам приходилось использовать такие инструменты, как sp_BlitzCache, чтобы выяснить, какие функции вызываются, и как часто.
Теперь вы можете видеть, что SQL Server создает катушку, или, говоря по другому, пассивно-агрессивно создает свой собственный отсутствующий индекс «на лету», не утруждая себя тем, что ему это нужно (обратите внимание, что в плане нет отсутствующего запроса индекса):

Наложение очереди
Замечательно! Это означает, что мы можем легко исправить это, просто сделав настройку индекса. Конечно, мы должны знать, как сделать этот уровень настройки индекса - но это пара пустяков, когда внезапно план делает его более очевидным в отношении того, что он действительно делает.
Как узнать, будут ли ваши функции работать быстрее
В документации перечислены многие конструкторы T-SQL, которые будут или не будут включены:
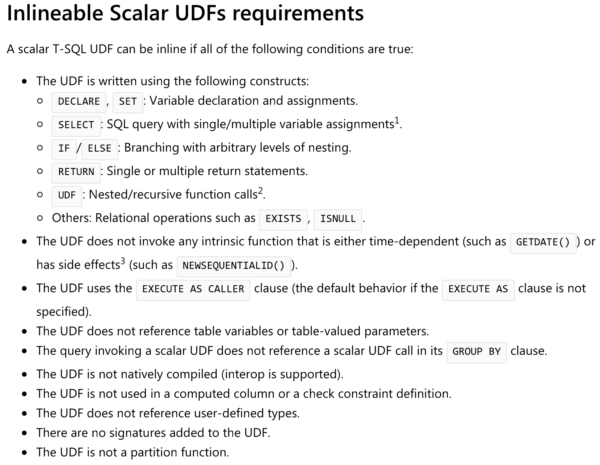
Но чтение этого потребует от вас также открыть код в ваших пользовательских функциях, и это одна из главных причин профессионального убийства данных. Мне нужны все считыватели, которых я могу получить.
Поэтому вместо этого просто загрузите предварительный просмотр SQL Server 2019, установите его на тестовую виртуальную машину, восстановите в ней базу данных и запустите:
|
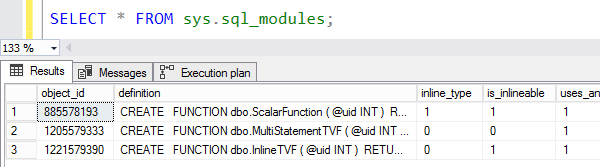
SELECT * FROM sys.sql_modules; |
Существует новый столбец is_inlineable, в котором указывается, какие из ваших функций могут быть встроены:
Затем, чтобы узнать, какие из ваших функций на самом деле вызываются наиболее часто в производстве сегодня, используйте sp_BlitzCache:
sp_BlitzCache @SortOrder = 'executions';
Сделайте инвентаризацию этих данных, и пока вы там смотрите функции, попробуйте CPU, Reads или Memory Grant в качестве разных заказов сортировки. Следите за табличными переменными, большими или низкими Memory Grants, которые приводят к вытеснениям, поскольку SQL Server 2019 также улучшает их:
- Что нового в SQL Server 2019: более быстрые переменные таблицы
- Что нового в SQL Server 2019: Адаптивные Memory Grants
Это поможет вам построить бизнес-кейс для управления. Вы сможете объяснить, какие из ваших запросов будут волшебным образом запускаться быстрее, как только вы обновите, и насколько это будет иметь влияние на ваш SQL Server в целом - без изменения кода. Это особенно важно для сторонних приложений, где вы не можете изменить код, и вам нужно повысить производительность.