Большие данные
В этой статье объясняется практический пример обработки больших данных (> peta byte = 10 ^ 15 байт) с использованием hadoop с определением множества кластеров с помощью spark и вычислением тяжелых вычислений с помощью библиотек tensorflow в python.
Введение
В настоящее время мы сталкиваемся с явлениями роста объема данных. Наше желание, чтобы сохранить все эти данные в течение длительного времени и процесса и анализировать их с высокой скоростью спровоцировало потребность построить хорошее решение для этого. Поиск подходящей замены для традиционных баз данных, которая может хранить любой тип структурированных и неструктурированных данных, является самой сложной задачей для ученых по данным.
Мы выбрали полный сценарий с первого шага до результата, который трудно найти, например, во всем Интернете. Мы выбрали MapReduce, который обрабатывает данные с использованием hadoop и scala внутри идеи intellij, в то время как вся эта история будет происходить под Linux ubuntu в качестве операционной системы.
Насколько большими могут быть данные?
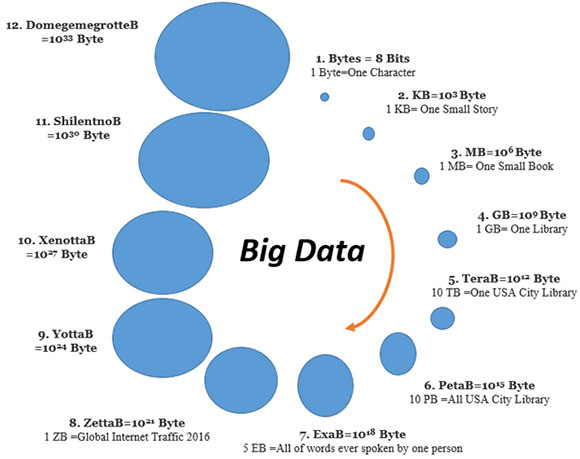
Что такое большие данные?
Большие данные - это огромный объем массивных данных, которые структурированы, неструктурированы или полуструктурированы, и их трудно хранить, трудно управлять традиционными базами данных. Его объем варьируется от терабайта до петабайт. Реляционные базы данных, такие как SQL Server, не подходят для хранения неструктурированных данных. Как вы видите на рисунке, большие данные представляют собой все виды структурированных или неструктурированных данных, которые имеют фундаментальные требования, такие как хранение, управление, совместное использование, анализ.
Большим данным необходим процесс импорта и потоковой передачи огромных данных в ящик для хранения данных для обработки и анализа данных.
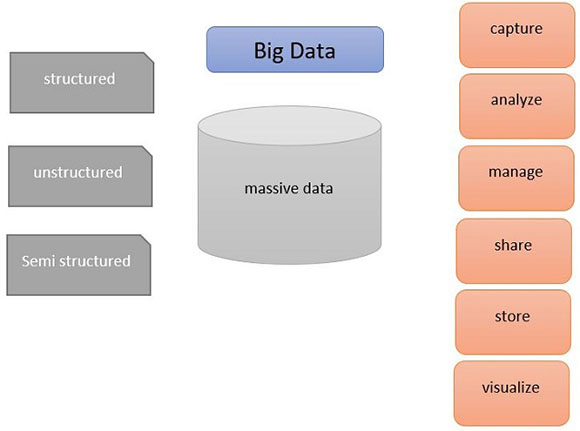
В больших данных есть две важные проблемы:
- Сбор большого объема данных. (например, импорт, передача и загрузка данных)
- Анализ данных. (например, процесс, сортировка, подсчет, агрегирование данных)
Для выполнения вышеуказанных шагов нам необходимо установить систему сообщений. Система сообщений - это решение для передачи данных из одного приложения в другое. Существует два типа системы обмена сообщениями: “точка-точка” и публикация подписчика. В отправке сообщения может быть использовано только один потребитель, тогда как в системе сообщений pub-sub потребитель может использовать более одной темы от публикатора.
Типы обработки
Непрерывная обработка
При непрерывной обработке обрабатывается только одна задача. Эта обработка - противоположность пакетной обработки.
Асинхронная обработка
При асинхронной обработке каждая задача будет обрабатываться в отдельном потоке. Он может выполнять несколько задач одновременно. Основное различие между синхронизацией и асинхронизацией - это параллельный процесс для нескольких задач.
Представьте два типа заказа еды, при одном вы покупаете еду, например шаурму, на улице (процесс синхронизации), при другом - заказываете в ресторане (процесс асинхронизации). В первом случае мы ждем, пока люди в очереди перед нами не получат свою шаурму, в то время как в ресторане выполнение нашего заказа зависит от свободного повара и места на кухне.
Пакетная обработка - Off Line
В пакетной обработке сначала необходимо расположить хранилище данных на диске, которое может быть включено в миллион записей, а затем будет происходить обработка, анализ для всех этих огромных данных. Hadoop через MapReduce - хороший образец. В пакетной обработке нет необходимости знать экземпляр и немедленный результат в реальном времени. Это полезно для анализа больших данных в автономном режиме.
Потоковая обработка - в реальном времени
В потоковой обработке сначала данные будут вводиться в аналитические инструменты, такие как Spark или Storm, а затем данные немедленно будут анализироваться. Это решение подходит для обработки нескольких недавних записей, которые необходимы для ответа экземпляра, таких как системы аутентификации или авторизации. Этот процесс выполняется быстро из-за обработки в памяти, а не на диске. Он имеет высокую задержку из-за меньшего количества записей для анализа и в памяти.
Основные и смежные понятия
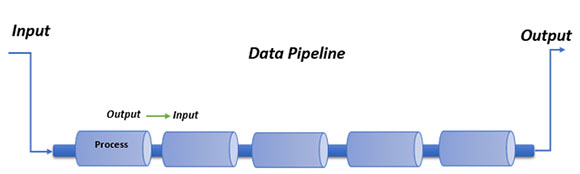
Что такое конвейер данных?
Конвейер данных представляет собой серию соединенных и связанных элементов, каждая из которых содержит данные процесса, чтобы сделать их повторно используемыми для следующего элемента, а также производить гибкий вывод с желаемой формой и форматом.
Латентность:
Длительность передачи данных с одной точки на другую. Низкая латентность показывает высокую эффективность сети.
Пропускная способность:
Целый ряд всех действий в определенное время от начала до отправки до завершения в конце процесса.
Надежность:
Надежные системы гарантируют, что все данные будут обработаны должным образом без сбоев, а в случае сбоя он будет повторно выполнять его.
Отказоустойчивость:
Системы отказоустойчивости гарантируют, что все данные будут сохранены надлежащим образом без сбоев, это означает, что когда кластер был разбит, конкретная задача будет направлена на другую машину.
Долговечность:
Когда процесс будет завершен, успешное сообщение будет отправлено клиенту. Несмотря на то, что приносит в жертву производительность, но заслуживает внимания.
Масштабируемость:
Масштабируемость будет определяться в основном распределенными системами и параллельным программированием. Это может гарантировать скорость роста трафика, а также данные.
Производительность:
Системы производительности гарантируют пропускную способность даже в случае обнаружения больших больших данных.
Без SQL
MongoDB
Монго был написан C ++. Он ориентирован на документ. Он является гибким для обработки данных со многими запросами.
Redis
Redis - хранилище данных с открытым исходным кодом и памятью в памяти с кешем и брокером сообщений.
Инструменты больших данных
Hadoop / Hbase
Это нереляционная и распределенная база данных с открытым исходным кодом. Apache HBase находится на вершине Hadoop.
Cassandra
Имеет хорошую масштабируемость, отказоустойчивость, а также более низкую латентность и отличное кэширование.
Потоковая передача данных
Flink
Это либо пакетная обработка, либо в режиме реального времени. Flink имеет API для потоковой передачи, sql-запрос.
Storm
Storm - это система реального времени с высокой производительностью и масштабируемостью. Он может обрабатывать более миллиона записей в секунду на узел.
Kinesis
Kinesis имеет обработку в реальном времени.
Kafka
Kafka - система публикации сообщений и подписки в режиме реального времени с хорошей производительностью, надежностью, масштабируемостью и долговечностью.
Что такое Hadoop?
На самом деле, мы ожидаем выполнения двух задач ото всех баз данных. Во-первых, нам нужно хранить данные, во-вторых, мы хотим быстро и точно обрабатывать сохраненные данные. Из-за произвольной формы и большого объема больших данных их невозможно хранить в традиционных базах данных. Нам нужно подумать о новой, которая может обрабатывать как хранение, так и обработку больших данных.
Hadoop - это революционная база данных для больших данных, которая имеет возможность сохранять любую форму данных и обрабатывать их кластер узлов. Это также значительно снижает стоимость обслуживания данных. С помощью hadoop мы можем хранить любые данные, например, весь пользовательский клик в течение длительного периода времени. Таким образом, он упрощает исторический анализ. Hadoop имеет распределенное хранилище, а также распределенную систему процессов, такую как Map Reduce.
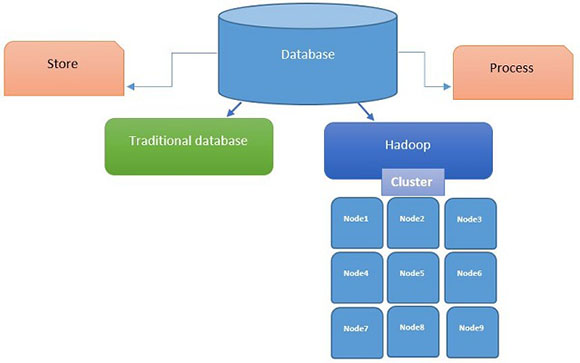
Что такое экосистема Hadoop?
Как было уже упомянуто выше, hadoop подходит для хранения неструктурированных баз данных или их обработки. Существует абстрактное определение для системы e-eudo. Сохранение данных расположено с левой стороны с двумя различными возможностями хранения, такими как HDFS и HBase. HBase - это вершина HDFS, и оба были написаны с помощью java.
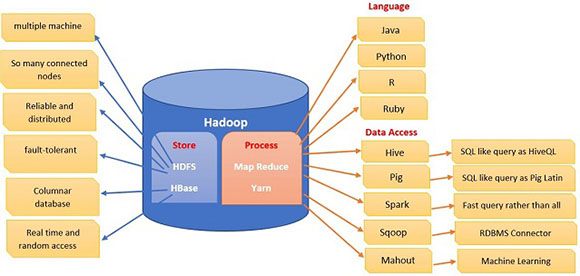
HDFS:
- Распределенная файловая система Hadoop позволяет хранить большие данные в распределенных плоских файлах.
- HDFS хорош для последовательного доступа к данным.
- Нет случайного доступа к данным в режиме чтения / записи в режиме реального времени. Это более подходит для автономной пакетной обработки.
HBase:
- Хранение data I в парах ключ / значение в столбчатом режиме.
- HBase имеет возможность чтения / записи в реальном времени.
Hadoop был написан в java, но также вы можете реализовать R, Python, Ruby.
Spark - это кластерное вычисление с открытым исходным кодом, которое реализовано в Scala и подходит для поддержки итерации работы при распределенных вычислениях. Spark имеет высокую производительность.
Hive, pig, Sqoop и mahout - это доступ к данным, которые делают возможным запрос к базе данных. Hive и pig похожи на SQL; mahout предназначен для машинного обучения.
MapReduce и Yarn работают для обработки данных. MapReduce построен для обработки данных в распределенных системах. MapReduce может обрабатывать все задачи, такие как отслеживание заданий и задач, мониторинг и выполнение в параллельном режиме.
Yarn (Yet Another Resource Negotiator) - это MapReduce 2.0, который имеет лучшее управление ресурсами и планирование.
Sqoop - это соединитель для импорта и экспорта данных из / во внешние базы данных. Это позволяет легко и быстро передавать данные в параллельном режиме.
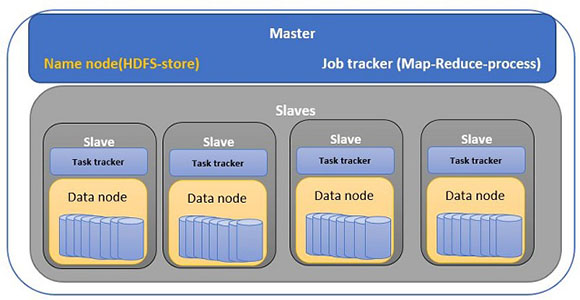
Как работает Hadoop?
Hadoop придерживается моделей архитектуры master / slaves. Для HDFS узел имен в основных мониторах и отслеживает все ведомые устройства, которые представляют собой группу кластера хранения
Существует два разных типа заданий, которые делают всю “магию” для обработки MapReduce. Работа с картой, которая отправляет запрос для обработки различных узлов в кластере. Эта работа будет разбита на меньшие задачи. Затем Reduce собирает все выходные данные, которые произвел каждый узел произвел, и объединяет их с одним значением в качестве конечного результата.
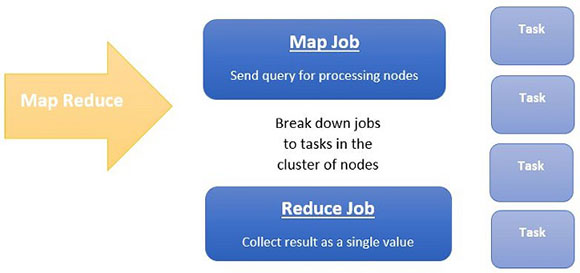
Эта архитектура делает Hadoop недорогим но при этом очень быстрым и надежным решением. Разделив большое задание на меньшие, каждая задача помещается в другой узел. Эта история может напоминать вам процесс многопоточности. При многопоточности все параллельные процессы совместно используются с помощью замков и семафоров, но доступ к данным в MapReduce находится под контролем HDFS.
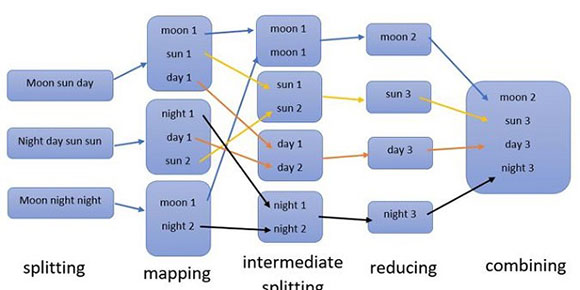
Практический пример
На приведенном ниже рисунке есть три текстовых файла для практического подсчета слов. MapReduce начинает разбивать каждый файл на кластер узлов, как мы показали в верхней части этой статьи. На этапе сопоставления каждый узел отвечает за подсчет слов. При промежуточном расщеплении в каждом узле есть просто однотипное слово и каждое число этого конкретного слова в предыдущем узле. Затем в восстановительной фазе каждый узел будет суммироваться и собирать собственный результат для получения одного значения.
Tensorflow в Windows - Python - CPU
Скачайте Anaconda Python 3.6
Если вы хотите легко чувствовать себя комфортно с помощью IDE и профессионального редактора, без установки библиотек, вы можете использовать Anaconda & Spider.
Затем откройте Anaconda Navigator от звезды и выберите и запустите «Spider»:
Есть несколько моментов:
- Python является объектно-ориентированным
- Динамический ввод текста
- Богатые библиотеки
- Простота чтения
- Python чувствителен к регистру
- Отступ имеет важное значение для Python
Установите Tensorflow
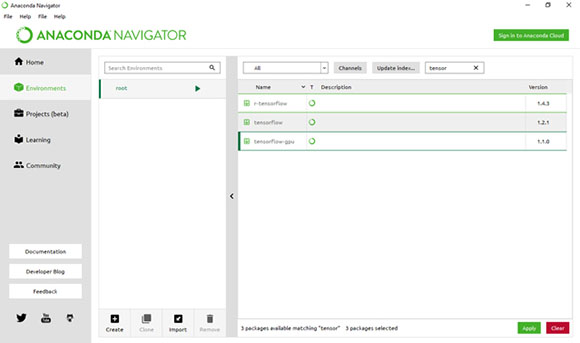
- Откройте Anaconda Naviator из «Start Menue» -> выберите "Environments" в левой панели -> Перейдите в "root" -> выберите "All Channels" -> найдите "tensor"
- Выберите «tensorflow», но если вы считаете, что вам нужно работать с R для статистических вычислений или GPU для получения быстрого результата, выберите «r-tensorflow» и «tensorflow-gpu».
- Затем нажмите зеленую кнопку «Apply».
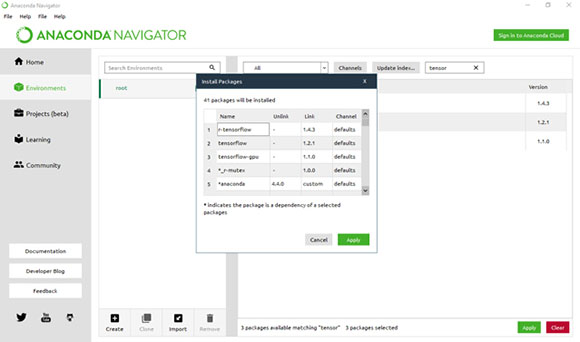
- Затем снова примите остальные пакеты, которые являются зависимыми, в следующем окне.
Что такое глубокое обучение?
На самом деле глубокое обучение - это отрасль машинного обучения. Машиноведение включает в себя несколько различных типов алгоритмов, которые получают несколько тысяч данных и пытаются учиться у них, чтобы предсказать новые события в будущем. Но глубокое обучение применяет нейронную сеть в виде расширенных или вариантных форм. Глубокое обучение позволяет обрабатывать миллионы точек данных.
Наиболее фундаментальной инфраструктурой глубокого обучения может быть его способность выбирать лучшие функции. Действительно, глубокое обучение суммирует данные и вычисляет результат на основе сжатых данных. Это то, что действительно необходимо в искусственном интеллекте, особенно когда у нас огромная база данных с резким вычислением.
Глубокое обучение имеет последовательные слои, которые вдохновлены нейронной сетью. Эти слои имеют нелинейную функцию с режимом выбора функции. Каждый слой имеет выход, который будет использоваться как вход для следующих слоев. Приложения для глубокого обучения - компьютерное зрение (например, распознавание лица или объекта), распознавание речи, процесс естественного языка (NLP) и обнаружение кибер-угроз.
Установка и внедрение Hadoop шаг за шагом
1. Загрузите и установите Java
Перейдите сюда, чтобы загрузить эту версию jdk1.8.0_144
Выберите диск (C:\Java) в качестве пути для установки.
2. Загрузите и установите Hadoop
Скачайте hadoop отсюда и поставьте диск (D:\), у вас должно получиться что-то вроде следующего.
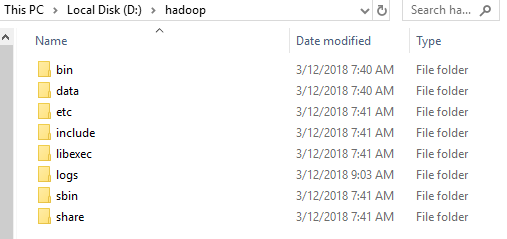
Сначала создайте новую папку и назовите ее «данные», если ее нет.
Формат
Запуск от имени администратора «Командная строка Windows»
D:\hadoop\bin>hadoop-data-dfs - remove all
D:\hadoop\bin>hadoop namenode -format
Запуск
1. D:\hadoop\sbin>start-dfs.cmd
(подождите одну минуту)
2. D:\hadoop\sbin>yarn-dfs.cmd
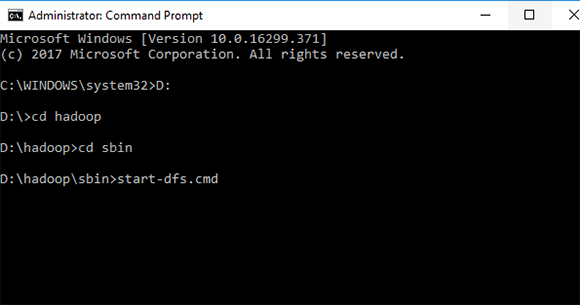
Вы увидите 4 окна:
1. yarn-resourcemanager
2. yarn-nodemanager
3. namenode
4. datanode
Итак, если вы увидели эти 4 окна, это означает, что все идет правильно.
Настройка среды
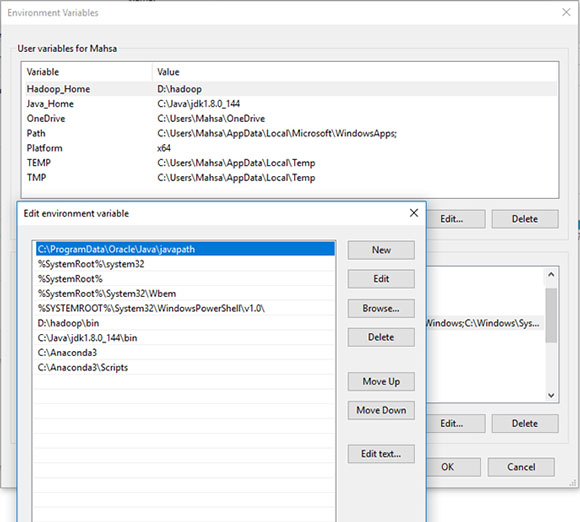
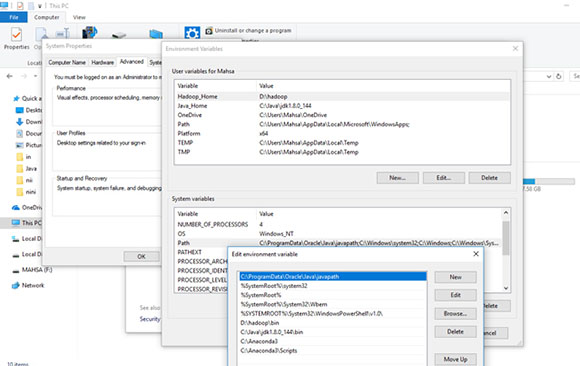
Протестируйте и запустите простой и известный код python как wordcount:
Создайте новую папку в папке D:\hdp, затем создайте и сохраните ниже python и текстовый файл.
wordcount-mapper.py
import sys
for line in sys.stdin: # Input is read from STDIN and the output of this file is written into STDOUT
line = line.strip() # remove leading and trailing whitespace
words = line.split() # split the line into words
for word in words:
print( '%s\t%s' % (word, 1)) #Print all words (key) individually with the value 1
wordcount-reducer.py
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin: # input comes from STDIN
line = line.strip() # remove leading and trailing whitespace
word, count = line.split('\t', 1) # parse the input we got from mapper.py by a tab (space)
try:
count = int(count) # convert count from string to int
except ValueError:
continue #If the count is not a number then discard the line by doing nothing
if current_word == word: #comparing the current word with the previous word (since they are ordered by key (word))
current_count += count
else:
if current_word:
# write result to STDOUT
print( '%s\t%s' % (current_word, current_count))
current_count = count
current_word = word
if current_word == word: # do not forget to output the last word if needed!
print( '%s\t%s' % (current_word, current_count))
Создайте текстовый документ "mahsa.txt"
Hello
Hello
Hello
Hello
Hello
Good
Good
Запустите его на hadoop
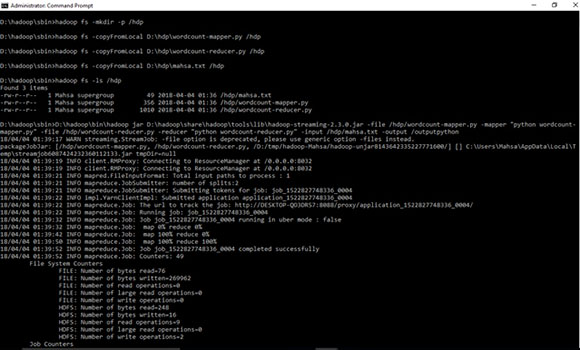
D:\hadoop\sbin>hadoop fs -mkdir -p /hdp
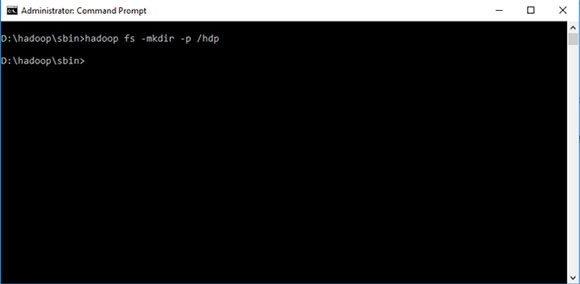
D:\hadoop\sbin>hadoop fs -copyFromLocal D:\hdp\wordcount-mapper.py /hdp
D:\hadoop\sbin>hadoop fs -copyFromLocal D:\hdp\wordcount-reducer.py /hdp
D:\hadoop\sbin>hadoop fs -copyFromLocal D:\hdp\mahsa.txt /hdp
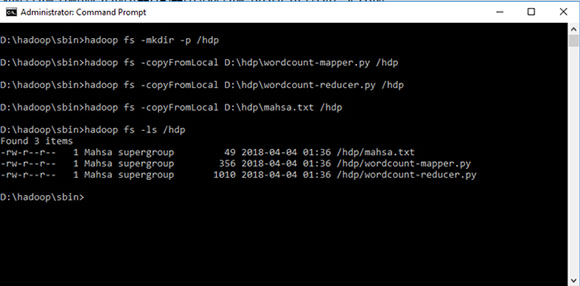
D:\hadoop\sbin>hadoop fs -ls /hdp
D:\hadoop\sbin>D:\hadoop\bin\hadoop jar D:\hadoop\share\hadoop\tools\lib\hadoop-streaming-2.3.0.jar -file /hdp/wordcount-mapper.py -mapper "python wordcount-mapper.py" -file /hdp/wordcount-reducer.py -reducer "python wordcount-reducer.py" -input /hdp/mahsa.txt -output /outputpython
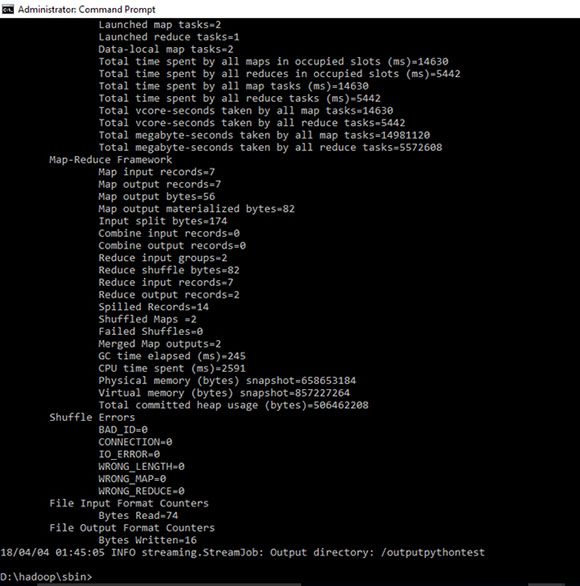


Протестируйте и запустите простой «Hello» с помощью кода python с тензорным потоком:
Создайте код на D:\hdp
# -*- coding: utf-8 -*- """ Created on Sun Apr 1 15:42:59 2018 @author: Mahsa """ import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!') sess = tf.Session() print(sess.run(hello))
D:\hadoop\sbin>hadoop fs -copyFromLocal D:\hdp\tensortest.py /hdp
D:\hadoop\sbin>D:\hadoop\bin\hadoop jar D:\hadoop\share\hadoop\tools\lib\hadoop-streaming-2.3.0.jar -D mapreduce.job.reduce=0 -file /hdp/tensortest.py -mapper "python tensortest.py" -input /hdp/mahsa.txt -output /outputtensortest
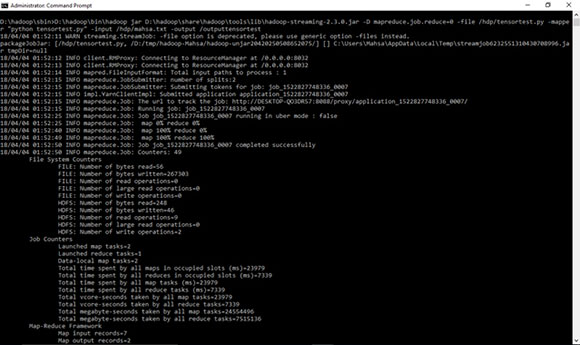
D:\hadoop\sbin>hadoop fs -ls /outputtensortest
D:\hadoop\sbin>hadoop fs -cat /outputtensortest/part-00000
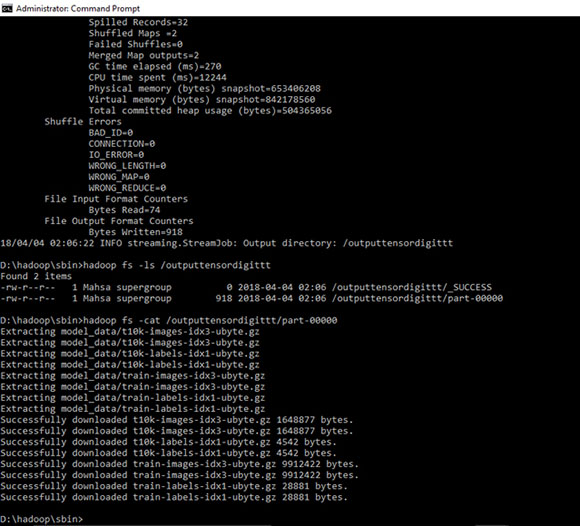
Протестируйте и запустите простую «Digit-Recognition» с помощью кода python с тензорным потоком:
Создайте код на D:\hdp
Создайте код на D:\hdp
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 1 15:42:59 2018
@author: Mahsa
"""
from tensorflow.examples.tutorials.mnist import input_data
# Downloading MNIS dataset
mnist_train = input_data.read_data_sets("data/", one_hot=True)
import tensorflow as tf
batch = 100
learning_rate = 0.01
training_epochs = 10
# matrix
x = tf.placeholder(tf.float32, shape=[None, 784])
yt = tf.placeholder(tf.float32, shape=[None, 10])
# Weight
Weight = tf.Variable(tf.zeros([784, 10]))
bias = tf.Variable(tf.zeros([10]))
# model
y = tf.nn.softmax(tf.matmul(x,Weight) + bias)
# entropy
cross_ent = tf.reduce_mean(-tf.reduce_sum(yt * tf.log(y), reduction_indices=[1]))
# Prediction
correct_pred = tf.equal(tf.argmax(y,1), tf.argmax(yt,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Gradient Descent
train_optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_ent)
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
# Batch Processing
for epoch in range(training_epochs):
batch_num = int(mnist_train.train.num_examples / batch)
for i in range(batch_num):
batch_x, batch_y = mnist_train.train.next_batch(batch)
sess.run([train_optimizer], result={x: batch_x, yt: batch_y})
if epoch % 2 == 0:
print( "Epoch: ", epoch)
print ("Accuracy: ", accuracy.eval(result={x: mnist_train.test.images, yt: mnist_train.test.labels}))
print( "Complete")
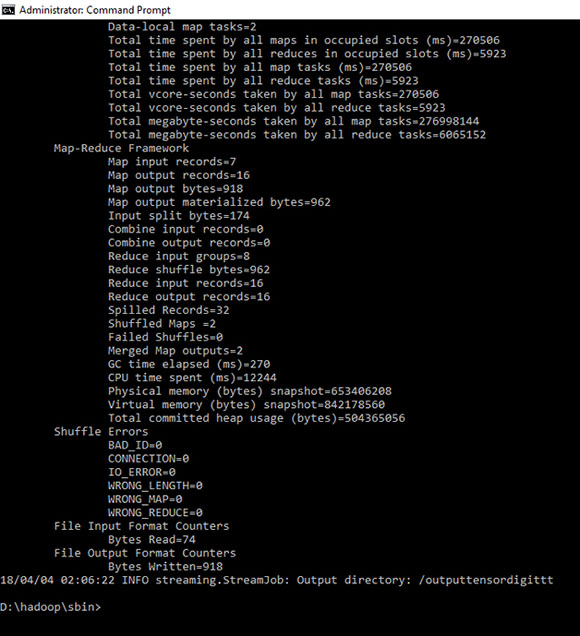
D:\hadoop\sbin>D:\hadoop\bin\hadoop jar D:\hadoop\share\hadoop\tools\lib\hadoop-streaming-2.3.0.jar -D mapreduce.job.reduce=0 -file /hdp/tensordigit.py -mapper "python tensordigit.py" -input /hdp/mahsa.txt -output /outputtensordigitt
D:\hadoop\sbin>hadoop fs -ls /outputtensordigittt