Azure Databricks - часть 1
Databricks - это аналитический сервис, основанный на проекте с открытым исходным кодом Apache Spark. Databricks использовался для поглощения значительного количества данных. В феврале 2018 года появилась интеграция между Azure и Databricks. Эта интеграция обеспечивает науку о данных и инженеров данных быстрой, простой платформой совместного использования на базе Spark в Azure. Azure Databricks - это новая платформа для аналитики больших данных и машинного обучения. Azure Databricks подходит инженерам данных, ученым с данными и бизнес-аналитикам. В этом посте и следующем будет представлен обзор того, что такое Azure Databricks. Мы покажем, как устроена среда и как ее использовать для науки о данных.
Среда Databricks
Создайте Azure Databricks в среде Azure. Войдите в одну из ваших учетных записей в среде Azure, создайте модуль Azure Databricks.
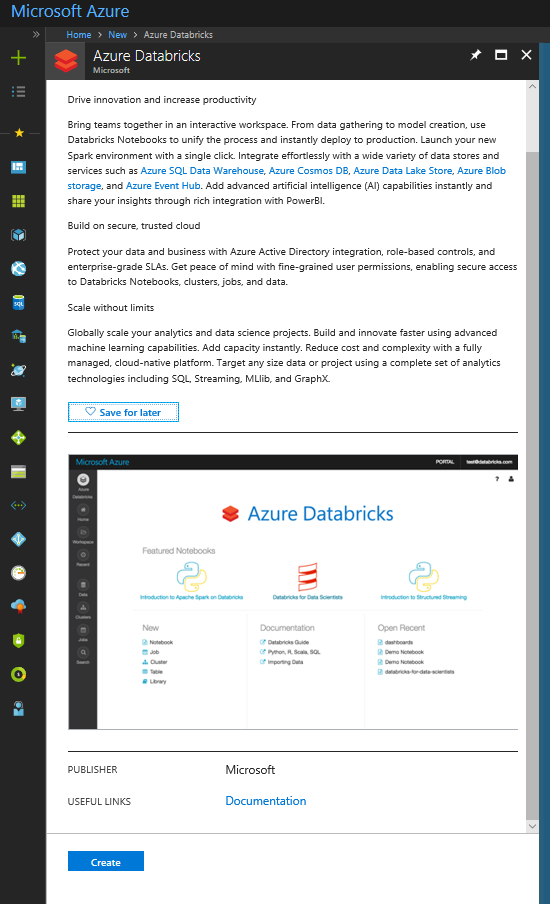
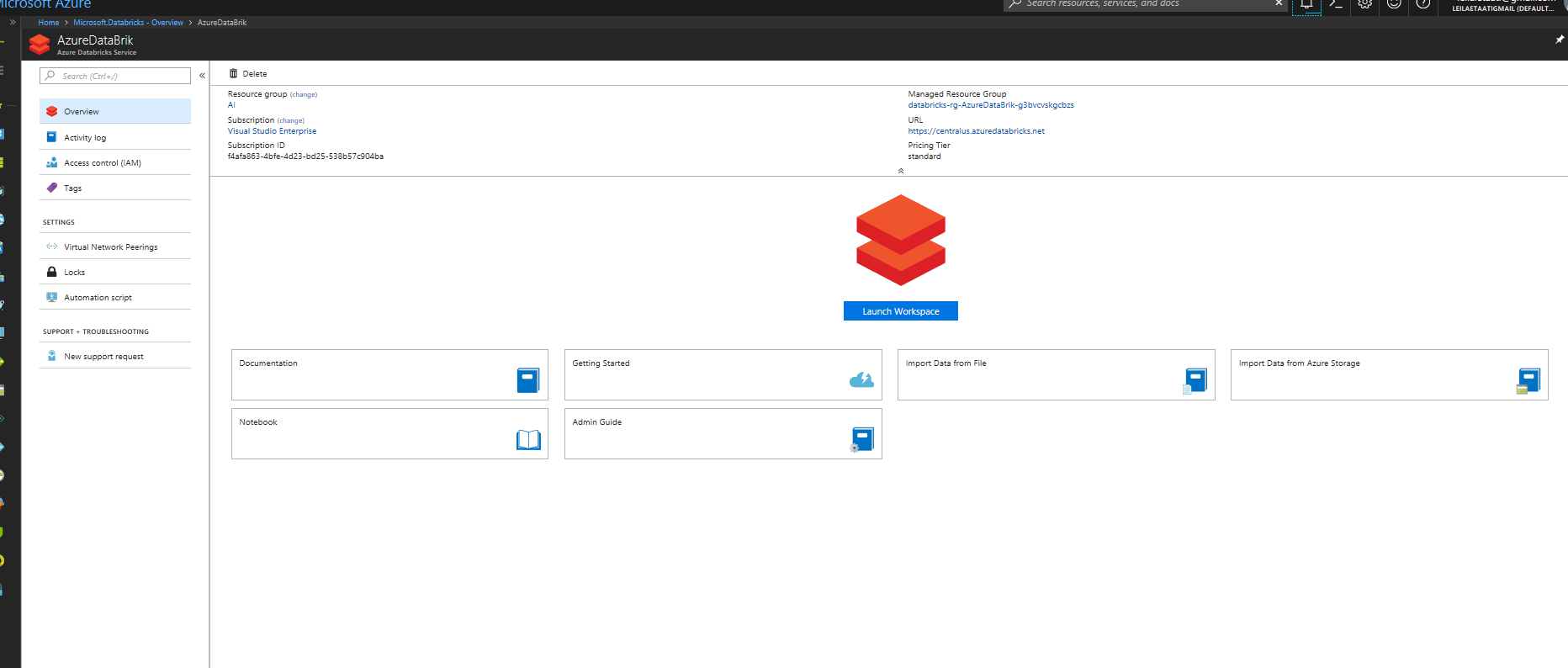
Чтобы получить доступ к Azure Databricks, выберите Launch Workspace.
Как видно на рисунке ниже, среда Azure Databricks имеет разные компоненты. Основными компонентами являются Workspace и Cluster. Первый шаг - создание кластера. Кластеры в Databricks предоставляют единую платформу для ETL (Extract, transform и load), аналитику потоков и машинное обучение. Кластер имеет два типа: Interactive и Job. Кластеры Interactive используются для совместного анализа данных. Однако кластеры Job используются для быстрой и надежной автоматической загрузки с использованием API.
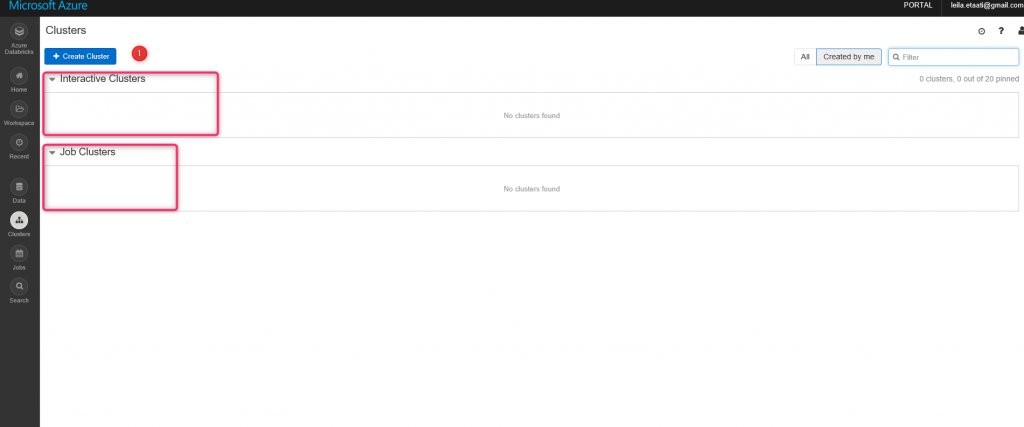
Страница кластера может содержать оба типа кластеров. Каждый кластер может иметь разные узлы. Сначала вам нужно создать кластер. Нажмите кнопку «Create Cluster ». На открывшейся странице введите информацию, такую как имя кластера, версию (по умолчанию), версию Python, и т.д.
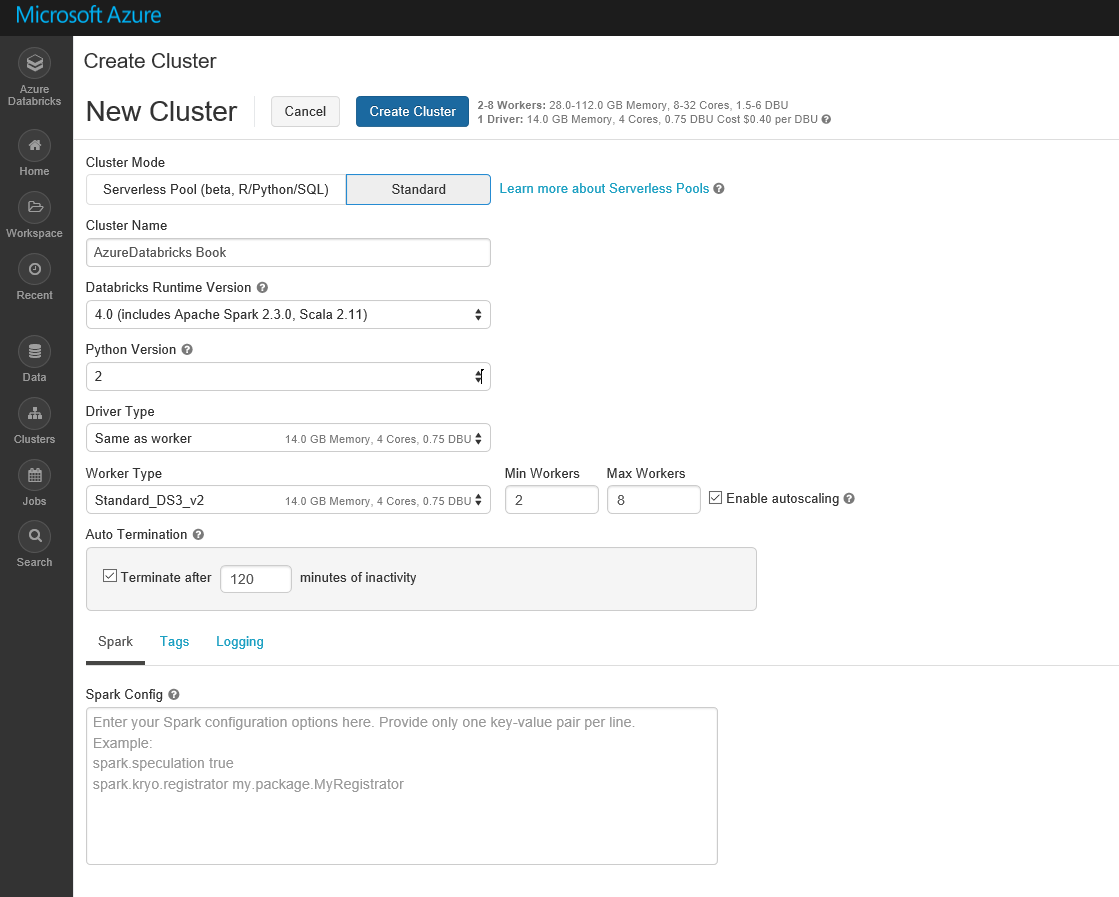
Чтобы использовать кластер, вы должны дождаться завершения изменения статуса (см. Ниже). Создавая интерактивный кластер, мы можем создать ноутбук для написания там кодов и быстро получить результат.

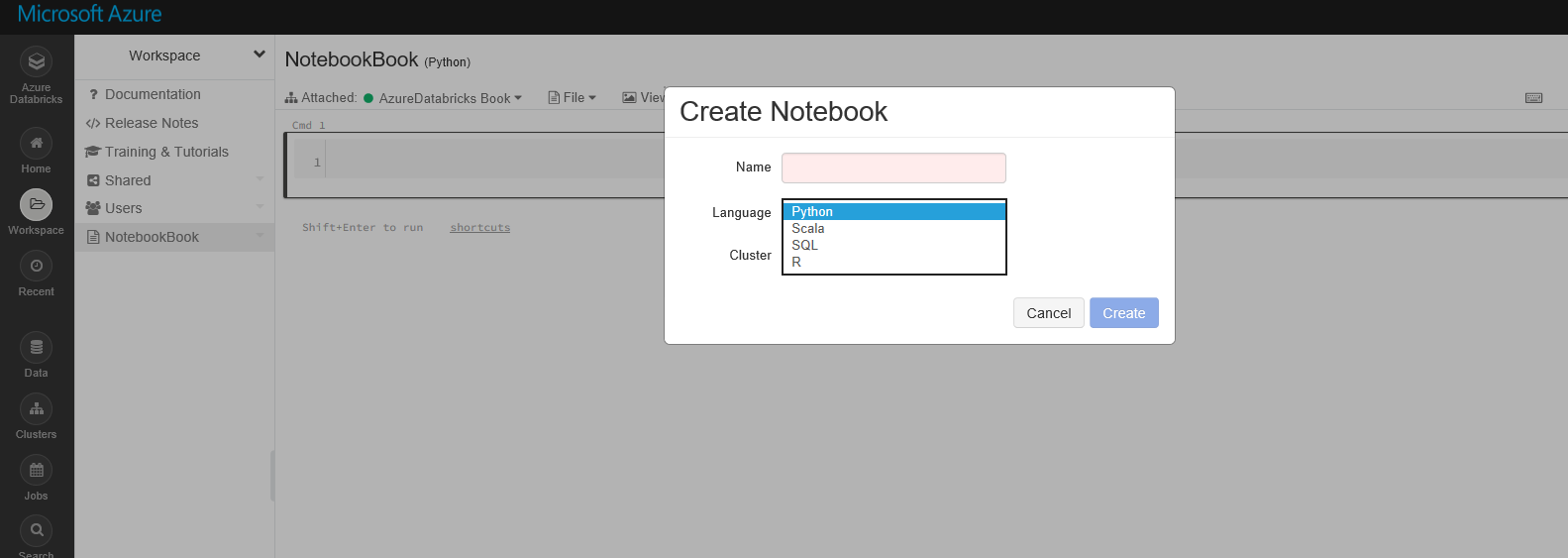
Чтобы создать ноутбук, нажмите кнопку Workspace и создайте новый ноутбук.
При создании нового ноутбука вы можете указать, какой ноутбук принадлежит кластеру, и каков основной язык для ноутбука (Python, Scala, R и SQL). В этом примере выбран R-язык по умолчанию. Однако вы можете писать другие языки на своем ноутбуке, написав:% scala. % python,% sql или% r перед скриптами.
В адресной книге есть место для написания кодов по умолчанию. Как вы можете видеть на рисунке ниже, есть редактор с именем cmd1 как узел для написания кодов и их запуска. В этом примере есть только один узел, а основным языком для написания кода является R. В этом примере мы используем существующий набор данных в пакете gpplot2 с именем mpg, записывая приведенные ниже коды.
library(ggplot2)
display(mpg)
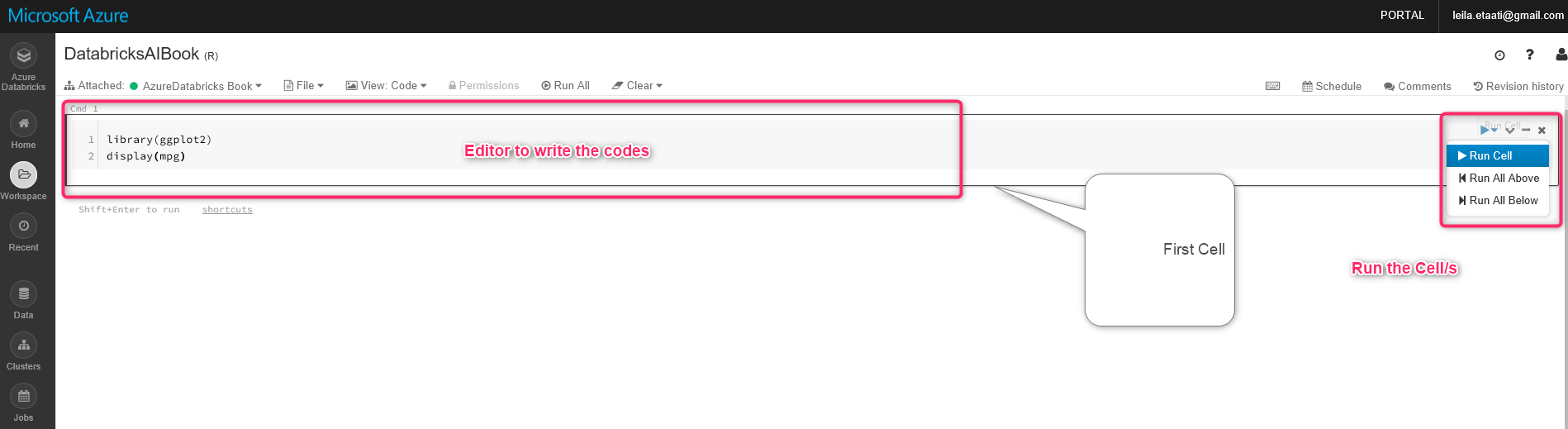
Выставите команду, покажите набор данных в Databricks. Чтобы запустить код, щелкните по стрелке в правой части узла и выберите Run Cell. После запуска кода результат появляется в конце ячейки со стилем таблицы.
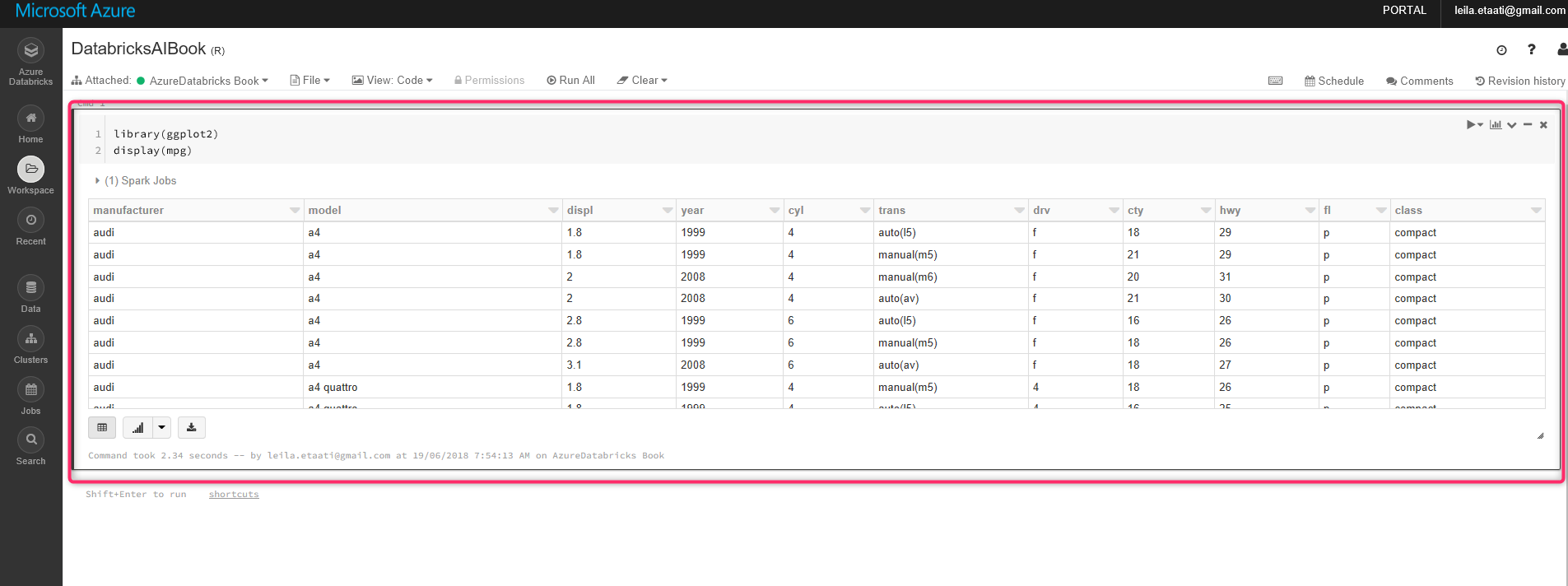
Чтобы показать график, вам нужно щелкнуть по значку диаграммы в нижней части ячейки.
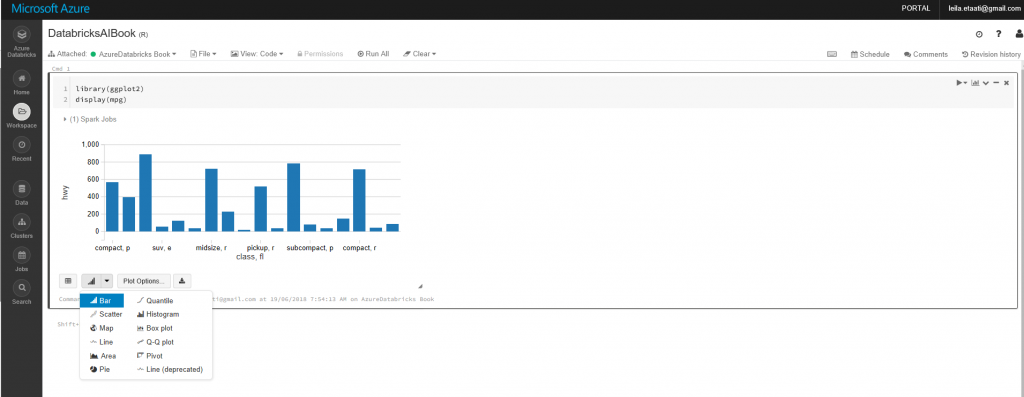
Кроме того, вы можете изменить элемент, который вы хотите отобразить на диаграмме, нажав на параметры диаграммы.
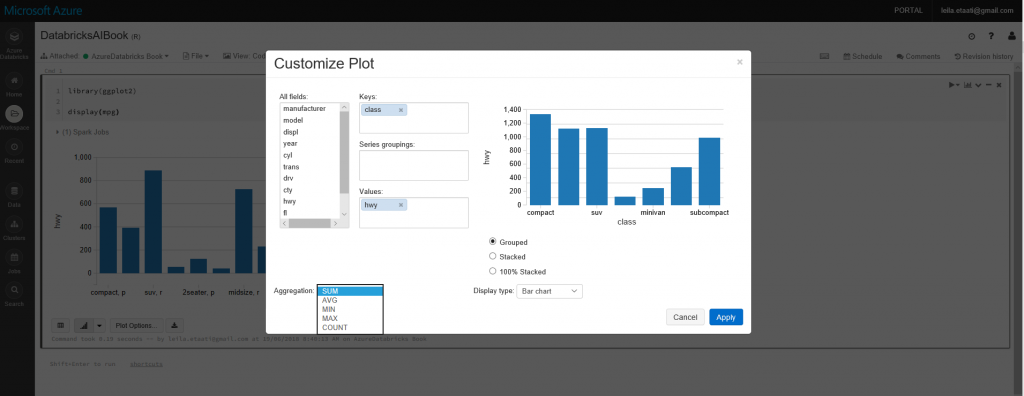
Это очень простой пример использования Databricks для запуска R-скриптов. В следующем посте мы покажем вам, как получить данные из Azure Data Lake Store, очистить его языком Scala, затем применить к нему машинное обучение и, наконец, отобразить его в Power BI.