Аналитика в HDInsight
Azure HDInsight - это аналитика с открытым исходным кодом и облачная базовая служба. Azure HDInsight легка, быстра и экономична для обработки огромных объемов данных. Существует много различных сценариев использования для HDInsight, таких как извлечение, преобразование и загрузка (ETL), хранилище данных, машинное обучение, IoT и т. д.
Основное преимущество использования HDInsight для машинного обучения - это доступ к инфраструктуре обработки на основе памяти. HDInsight помогает разработчикам обрабатывать и анализировать большие данные и разрабатывать решения, используя отличные и открытые исходные среды, такие как Hadoop, Spark, Hive, LLAP, Kafka, Storm и Microsoft Machine Learning Server .
Настройка кластеров в HDInsight
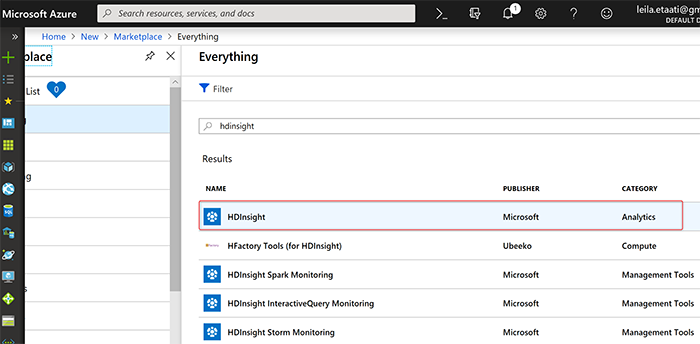
Первый шаг - настройка HDInsight в Azure. Войдите в свою учетную запись Azure и создайте компонент HDInsight в Azure. Как вы можете видеть на рисунке ниже, существуют различные модули для HDInsight, такие как мониторинг HDInsight Spark и мониторинг интерактивного запроса HDInsight. Среди них выбирается опция аналитики HDInsight.
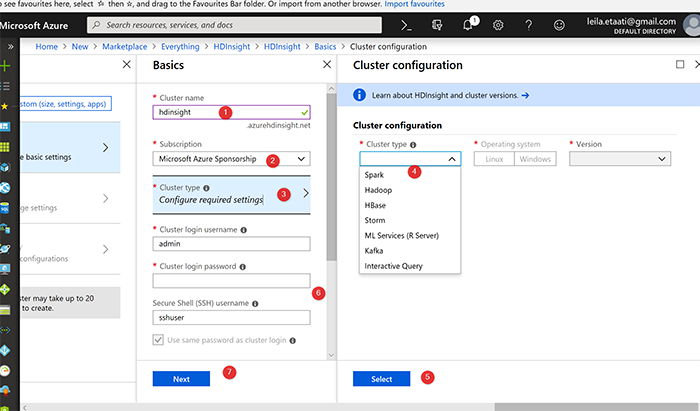
Когда вы создаете HDInsight, вам нужно выполнить несколько шагов для настройки кластера и определения размера. На первом этапе вам нужно установить имя кластера, установить подписку и тип кластера. Существуют различные типы кластеров, такие как Spark, Hadoop, Kafka, ML Services и т. д.
На следующем шаге вы должны определить размер и проверить сводку.
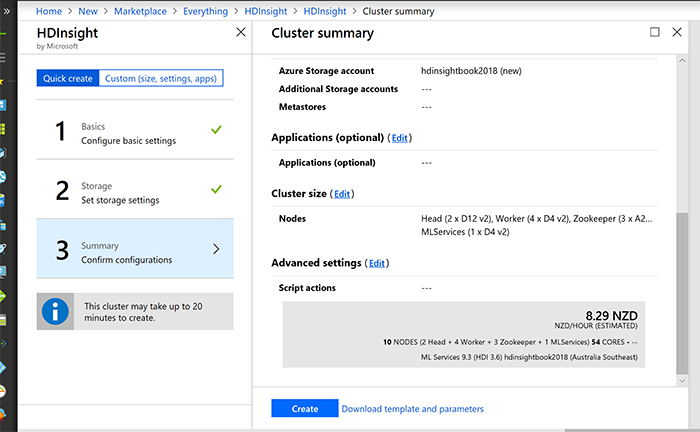
Создание HDInsight занимает пару минут. После создания компонента HDInsight на главной странице в разделе «Overview» выберите «Cluster Dashboard»
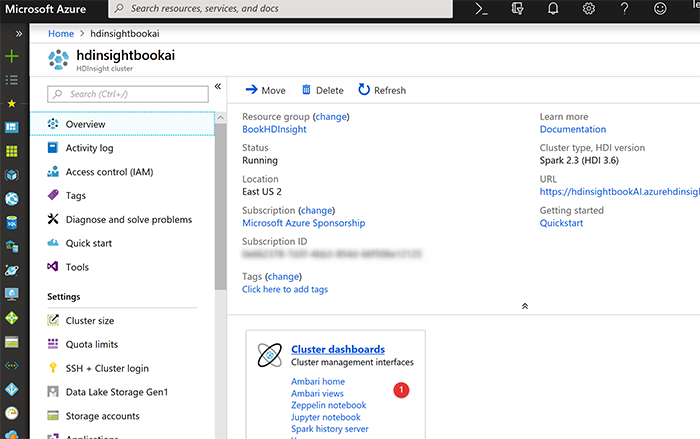
Затем выберите Jupyter Notebook на новой странице, выберите вариант «New».
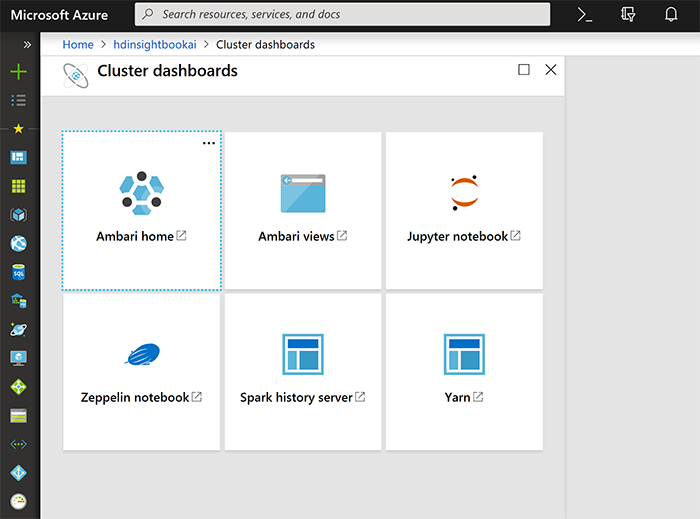
Как вы можете видеть на рисунке ниже, существуют различные варианты, такие как PySpark, PySpark3 и Spark notebook. Вы можете написать код python во всех из них. После создания новой страницы для Spark необходимо войти в систему с именем пользователя и паролем, которые вы предоставили для создания компонента HDInsight. Окружающая среда Jupyter похожа на ноутбук и, как на окружающую среду Azure Databricks. Кроме того, есть возможность написать код там и запустить целую ячейку, чтобы увидеть результат.
Существует возможность получить данные от других компонентов Azure, таких как Azure Data Lake Store Gen1. Для этого вам нужно запустить приведенные ниже коды (в Databricks мы запускаем тот же код).
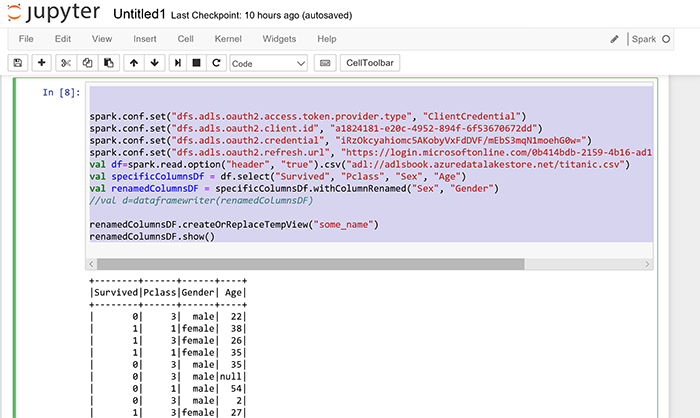
|
spark.conf.set(“dfs.adls.oauth2.access.token.provider.type”, “ClientCredential”) spark.conf.set(“dfs.adls.oauth2.client.id”, “a1824181-e20c-4952-894f-6f53670672dd”) spark.conf.set(“dfs.adls.oauth2.credential”, “iRzOkcyahiomc5AKobyVxFdDVF/mEbS3mqN1moehG0w=”) spark.conf.set(“dfs.adls.oauth2.refresh.url”, “https://login.microsoftonline.com/0b414bdb-2159-4b16-ad13-b2d54a1781da/oauth2/token”) val df=spark.read.option(“header”, “true”).csv(“adl://adlsbook.azuredatalakestore.net/titanic.csv”) val specificColumnsDf = df.select(“Survived”, “Pclass”, “Sex”, “Age”) val renamedColumnsDF = specificColumnsDf.withColumnRenamed(“Sex”, “Gender”) renamedColumnsDF.createOrReplaceTempView(“some_name”) renamedColumnsDF.show() |